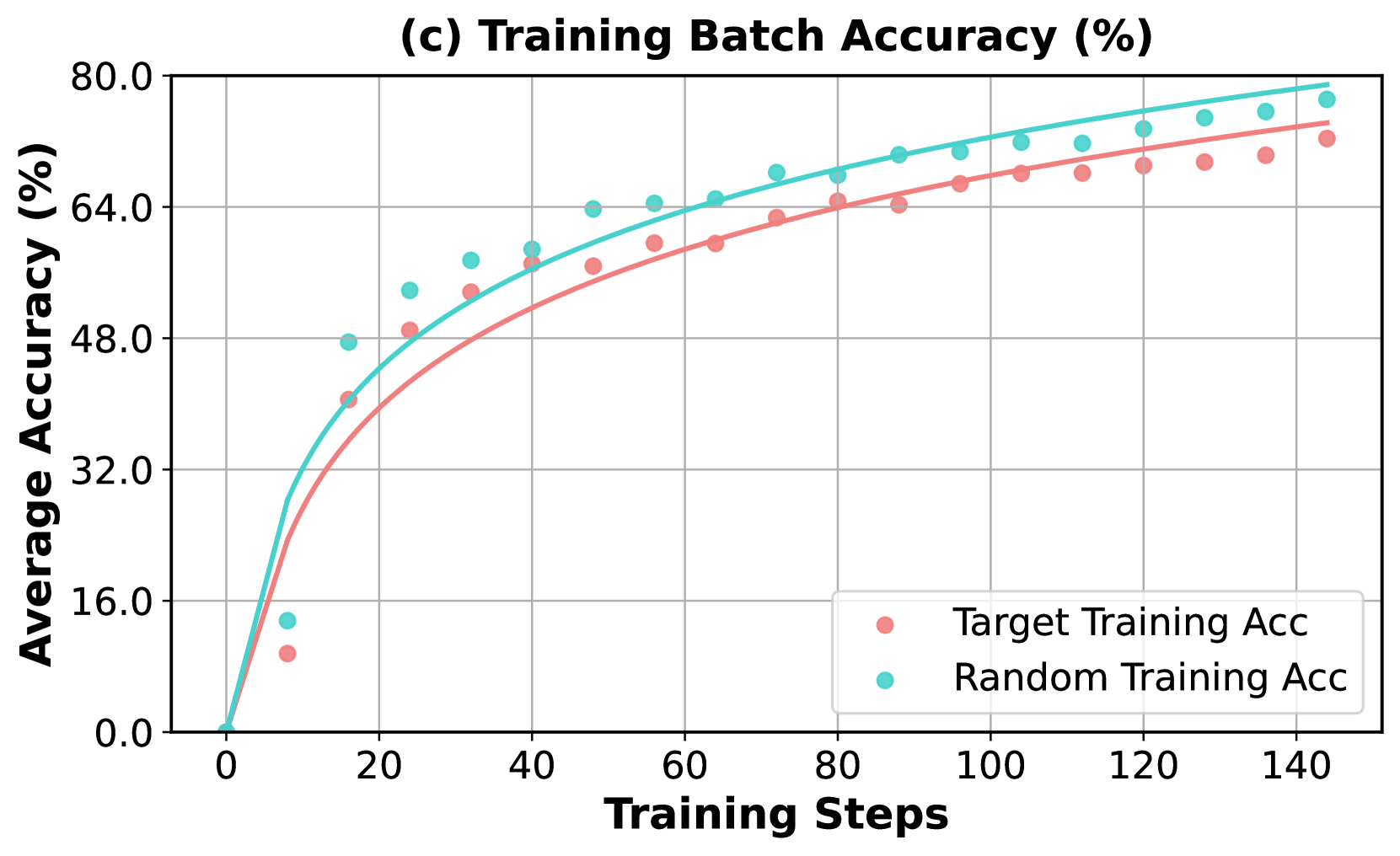
## Chart: Training Batch Accuracy
### Overview
The image is a line chart comparing the training accuracy of a "Target Training" model versus a "Random Training" model over a number of training steps. The chart displays the average accuracy (%) on the y-axis and the training steps on the x-axis. Both models show an increase in accuracy as the training steps increase, but the "Random Training" model consistently outperforms the "Target Training" model.
### Components/Axes
* **Title:** (c) Training Batch Accuracy (%)
* **X-axis:** Training Steps, with markers at 0, 20, 40, 60, 80, 100, 120, and 140.
* **Y-axis:** Average Accuracy (%), with markers at 0.0, 16.0, 32.0, 48.0, 64.0, and 80.0.
* **Legend:** Located in the bottom-right corner.
* **Target Training Acc:** Represented by a light red line and data points.
* **Random Training Acc:** Represented by a light blue/cyan line and data points.
### Detailed Analysis
* **Target Training Acc (Light Red):**
* The line starts at approximately 2% accuracy at 0 training steps.
* The line increases rapidly initially, reaching approximately 40% accuracy by 40 training steps.
* The rate of increase slows down, reaching approximately 65% accuracy by 120 training steps.
* The line ends at approximately 72% accuracy at 140 training steps.
* **Random Training Acc (Light Blue/Cyan):**
* The line starts at approximately 0% accuracy at 0 training steps.
* The line increases rapidly initially, reaching approximately 50% accuracy by 40 training steps.
* The rate of increase slows down, reaching approximately 72% accuracy by 120 training steps.
* The line ends at approximately 77% accuracy at 140 training steps.
### Key Observations
* Both models exhibit a logarithmic-like growth in accuracy, with rapid initial gains followed by diminishing returns.
* The "Random Training Acc" model consistently outperforms the "Target Training Acc" model throughout the training process.
* The gap between the two models appears to narrow slightly as the number of training steps increases.
### Interpretation
The chart suggests that the "Random Training" approach is more effective than the "Target Training" approach in this specific scenario. The rapid initial gains indicate that both models learn quickly at the beginning, but the "Random Training" model maintains a higher accuracy throughout. The narrowing gap between the two models at later stages of training could indicate that the "Target Training" model is gradually catching up, but it never surpasses the "Random Training" model within the observed training steps. This could be due to a variety of factors, such as the initial parameter settings, the training data distribution, or the specific algorithms used in each approach.