## Diagram: Multi-Head Attention Flow
### Overview
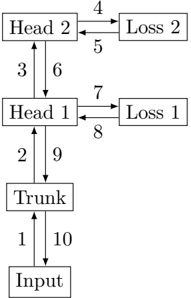
The image is a diagram illustrating the flow of information in a multi-head attention mechanism. It shows the relationships between the input, trunk, head, and loss components, with arrows indicating the direction of information flow.
### Components/Axes
* **Boxes:** Represent different components of the attention mechanism.
* Input
* Trunk
* Head 1
* Head 2
* Loss 1
* Loss 2
* **Arrows:** Indicate the direction of information flow between components.
* **Numbers:** Label the arrows, possibly indicating the sequence or type of operation.
### Detailed Analysis
The diagram shows the following flow of information:
1. **Input** to **Trunk**: Arrow labeled "1" indicates information flows from the Input to the Trunk.
2. **Trunk** to **Head 1**: Arrow labeled "2" indicates information flows from the Trunk to Head 1.
3. **Head 1** to **Head 2**: Arrow labeled "3" indicates information flows from Head 1 to Head 2.
4. **Head 2** to **Loss 2**: Arrow labeled "4" indicates information flows from Head 2 to Loss 2.
5. **Loss 2** to **Head 2**: Arrow labeled "5" indicates information flows from Loss 2 to Head 2.
6. **Head 2** to **Head 1**: Arrow labeled "6" indicates information flows from Head 2 to Head 1.
7. **Head 1** to **Loss 1**: Arrow labeled "7" indicates information flows from Head 1 to Loss 1.
8. **Loss 1** to **Head 1**: Arrow labeled "8" indicates information flows from Loss 1 to Head 1.
9. **Head 1** to **Trunk**: Arrow labeled "9" indicates information flows from Head 1 to Trunk.
10. **Trunk** to **Input**: Arrow labeled "10" indicates information flows from Trunk to Input.
### Key Observations
* The diagram illustrates a cyclical flow of information, with feedback loops between the heads and losses.
* The Trunk acts as a central processing unit, receiving input and distributing information to the heads.
* There are two heads (Head 1 and Head 2) and two corresponding losses (Loss 1 and Loss 2), suggesting a multi-head attention mechanism.
### Interpretation
The diagram represents a multi-head attention mechanism, where the input is processed by a trunk and then distributed to multiple heads. Each head computes attention weights and produces a loss, which is then fed back into the head. This cyclical flow of information allows the model to learn complex relationships between the input and output. The presence of multiple heads allows the model to attend to different parts of the input simultaneously, improving its ability to capture long-range dependencies. The feedback loops between the heads and losses enable the model to refine its attention weights and improve its performance.