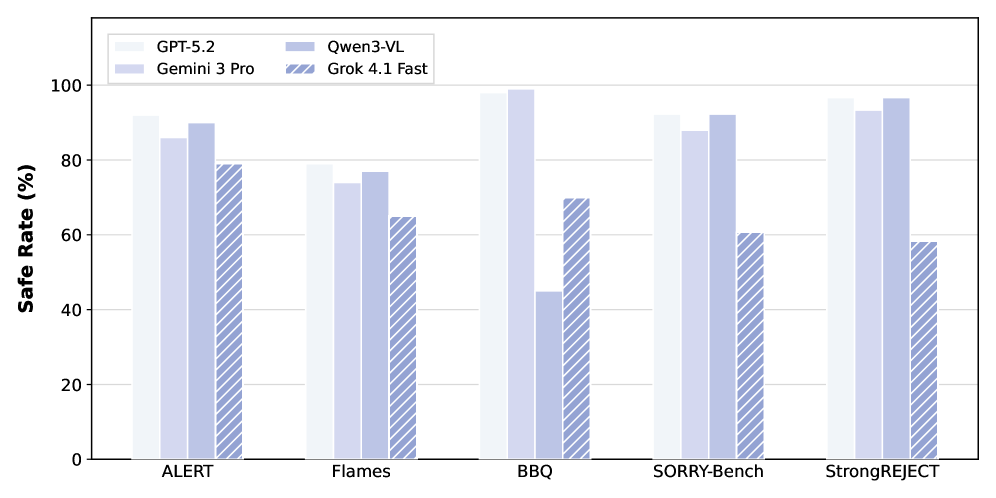
# Technical Data Extraction: AI Safety Benchmark Comparison
## 1. Document Overview
This image is a grouped bar chart comparing the performance of four Large Language Models (LLMs) across five different safety benchmarks. The performance metric is the "Safe Rate (%)".
## 2. Component Isolation
### A. Header / Legend
* **Location:** Top-left quadrant of the chart area.
* **Legend Items (Left to Right, Top to Bottom):**
1. **GPT-5.2**: Represented by a very light gray/off-white solid bar.
2. **Qwen3-VL**: Represented by a medium-light blue solid bar.
3. **Gemini 3 Pro**: Represented by a light lavender/blue solid bar.
4. **Grok 4.1 Fast**: Represented by a medium blue bar with white diagonal hatching (stripes).
### B. Main Chart Area (Axes)
* **Y-Axis Label:** Safe Rate (%) [Bold, Vertical orientation]
* **Y-Axis Scale:** 0 to 100, with major gridlines and markers every 20 units (0, 20, 40, 60, 80, 100).
* **X-Axis Categories (Benchmarks):**
1. ALERT
2. Flames
3. BBQ
4. SORRY-Bench
5. StrongREJECT
### C. Data Trends and Observations
* **GPT-5.2 (Solid Off-White):** Shows consistently high performance across all benchmarks, generally staying above 80% and peaking near 100% in BBQ.
* **Gemini 3 Pro (Solid Lavender):** Follows a similar high-performance trend to GPT-5.2, though slightly lower in most categories except BBQ, where it appears to be the top performer.
* **Qwen3-VL (Solid Medium-Light Blue):** Shows competitive performance in ALERT, Flames, and SORRY-Bench, but exhibits a significant performance drop in the BBQ benchmark.
* **Grok 4.1 Fast (Hatched Blue):** Consistently the lowest performer across all five benchmarks, with its highest safety rate in ALERT and its lowest in StrongREJECT.
## 3. Data Table Reconstruction
The following table estimates the numerical values based on the visual alignment with the Y-axis gridlines.
| Benchmark | GPT-5.2 (Off-white) | Gemini 3 Pro (Lavender) | Qwen3-VL (Light Blue) | Grok 4.1 Fast (Hatched) |
| :--- | :---: | :---: | :---: | :---: |
| **ALERT** | ~92% | ~86% | ~90% | ~79% |
| **Flames** | ~79% | ~74% | ~77% | ~65% |
| **BBQ** | ~98% | ~99% | ~45% | ~70% |
| **SORRY-Bench** | ~92% | ~88% | ~92% | ~61% |
| **StrongREJECT** | ~97% | ~93% | ~97% | ~58% |
## 4. Detailed Component Analysis
### Benchmark: ALERT
* **Trend:** High safety rates for all models.
* **Order:** GPT-5.2 > Qwen3-VL > Gemini 3 Pro > Grok 4.1 Fast.
### Benchmark: Flames
* **Trend:** A general dip in safety rates for all models compared to ALERT.
* **Order:** GPT-5.2 > Qwen3-VL > Gemini 3 Pro > Grok 4.1 Fast.
### Benchmark: BBQ
* **Trend:** High variance. GPT-5.2 and Gemini 3 Pro are near perfect. Qwen3-VL suffers its worst performance here.
* **Order:** Gemini 3 Pro > GPT-5.2 > Grok 4.1 Fast > Qwen3-VL.
### Benchmark: SORRY-Bench
* **Trend:** Recovery for Qwen3-VL; Grok 4.1 Fast remains significantly lower than the others.
* **Order:** GPT-5.2 ≈ Qwen3-VL > Gemini 3 Pro > Grok 4.1 Fast.
### Benchmark: StrongREJECT
* **Trend:** High performance for the first three models; Grok 4.1 Fast reaches its lowest point.
* **Order:** GPT-5.2 ≈ Qwen3-VL > Gemini 3 Pro > Grok 4.1 Fast.