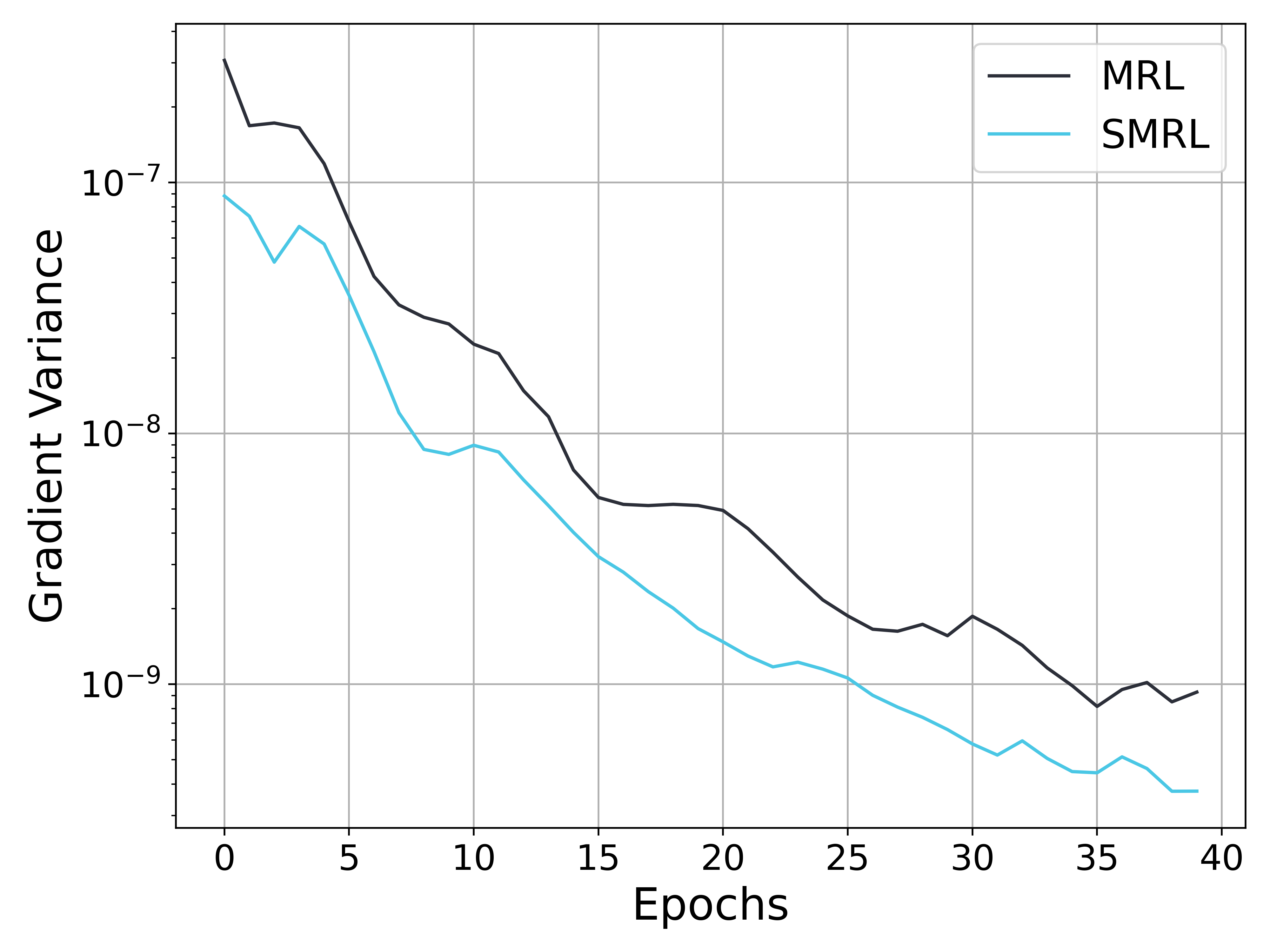
## Line Graph: Gradient Variance vs. Epochs for MRL and SMRL
### Overview
The image is a line graph comparing the gradient variance of two algorithms, MRL (black line) and SMRL (cyan line), across 40 epochs. The y-axis uses a logarithmic scale (10⁻⁹ to 10⁻⁷) to represent gradient variance, while the x-axis tracks epochs from 0 to 40. Both lines show a general downward trend, but with distinct decay rates.
---
### Components/Axes
- **X-axis (Epochs)**: Labeled "Epochs," ranging from 0 to 40 in increments of 5.
- **Y-axis (Gradient Variance)**: Labeled "Gradient Variance," with a logarithmic scale from 10⁻⁹ to 10⁻⁷.
- **Legend**: Located in the top-right corner, with:
- **Black line**: MRL
- **Cyan line**: SMRL
---
### Detailed Analysis
1. **MRL (Black Line)**:
- Starts at ~10⁻⁷ at epoch 0.
- Gradually decreases, reaching ~10⁻⁸ by epoch 10.
- Continues to decline, stabilizing near ~10⁻⁹ by epoch 40.
- Shows minor fluctuations (e.g., slight peaks at epochs 15 and 30) but maintains a consistent downward trajectory.
2. **SMRL (Cyan Line)**:
- Begins at ~10⁻⁸ at epoch 0.
- Declines more steeply, reaching ~10⁻⁹ by epoch 10.
- Continues to drop sharply, hitting ~10⁻¹⁰ by epoch 40.
- Exhibits a smoother, more linear decay compared to MRL.
---
### Key Observations
- **Decay Rates**: SMRL exhibits a faster gradient variance reduction than MRL, with a steeper slope on the logarithmic scale.
- **Stability**: MRL shows minor fluctuations but remains relatively stable after epoch 20, while SMRL’s decline is more aggressive.
- **No Intersection**: The lines do not cross, indicating SMRL consistently outperforms MRL in reducing gradient variance over time.
- **Logarithmic Scale Impact**: The y-axis compression emphasizes the magnitude differences, making SMRL’s faster decay visually dominant.
---
### Interpretation
The graph suggests that SMRL achieves a more rapid reduction in gradient variance compared to MRL, potentially indicating faster convergence or optimization efficiency. However, the minor fluctuations in MRL’s line might imply occasional instability or slower adaptation. The logarithmic scale highlights the exponential nature of gradient variance decay, emphasizing SMRL’s superior performance in early epochs. This could reflect differences in algorithm design, such as learning rate adjustments or regularization strategies. Further analysis of hyperparameters or loss landscapes would clarify the practical implications of these trends.