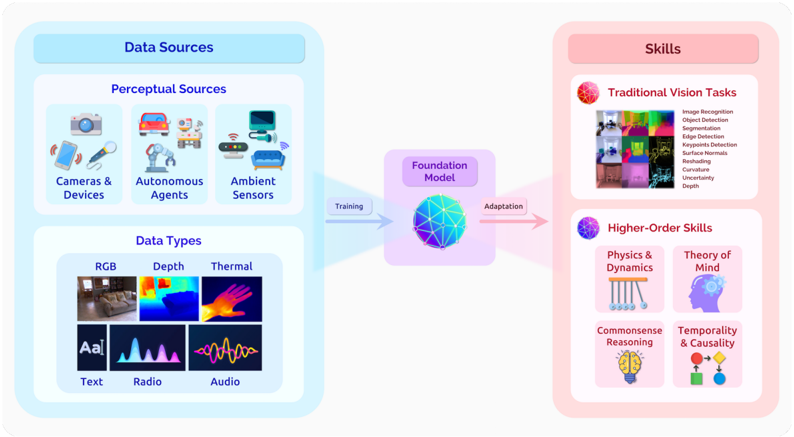
## Diagram: Foundation Model Training and Skills
### Overview
The image is a diagram illustrating the training and adaptation of a foundation model using various data sources to develop different skills. The diagram is divided into three main sections: Data Sources (left, light blue), Foundation Model (center), and Skills (right, light pink). Arrows indicate the flow of information from data sources to the model and then to the skills.
### Components/Axes
* **Data Sources (Left, light blue background)**
* **Perceptual Sources:**
* Cameras & Devices (icons of a camera, smartphone, and microphone)
* Autonomous Agents (icons of a car, a robot, and a drone)
* Ambient Sensors (icons of a TV, a speaker, and a couch)
* **Data Types:**
* RGB (image of a living room)
* Depth (depth map of a room)
* Thermal (thermal image of a hand)
* Text (icon of text with "Aa")
* Radio (waveform)
* Audio (waveform)
* **Foundation Model (Center)**
* A multicolored, faceted sphere representing the "Foundation Model"
* "Training" arrow pointing from Data Sources to the Foundation Model
* "Adaptation" arrow pointing from the Foundation Model to Skills
* **Skills (Right, light pink background)**
* **Traditional Vision Tasks:**
* Image Recognition
* Object Detection
* Segmentation
* Edge Detection
* Keypoints Detection
* Surface Normals
* Reshading
* Curvature
* Uncertainty
* Depth
* (Accompanied by a collage of images representing these tasks)
* **Higher-Order Skills:**
* Physics & Dynamics (icon of Newton's cradle)
* Theory of Mind (icon of a head with gears)
* Commonsense Reasoning (icon of a lightbulb)
* Temporality & Causality (icon of a flowchart with squares and circles)
### Detailed Analysis or ### Content Details
* **Data Sources:** The diagram categorizes data sources into perceptual sources (cameras, autonomous agents, ambient sensors) and data types (RGB, depth, thermal, text, radio, audio).
* **Foundation Model:** The model acts as a central processing unit, receiving data from various sources and adapting to develop different skills.
* **Skills:** The skills are divided into traditional vision tasks and higher-order skills. Traditional vision tasks include image recognition, object detection, segmentation, edge detection, keypoints detection, surface normals, reshaping, curvature, uncertainty, and depth. Higher-order skills include physics & dynamics, theory of mind, commonsense reasoning, and temporality & causality.
### Key Observations
* The diagram highlights the flow of information from diverse data sources to a foundation model, which then develops a range of skills.
* The skills are categorized into traditional vision tasks and higher-order skills, suggesting a hierarchy of complexity.
* The diagram emphasizes the importance of both perceptual data and abstract data types (text, radio, audio) in training the foundation model.
### Interpretation
The diagram illustrates a comprehensive approach to training a foundation model by leveraging diverse data sources and developing a wide range of skills. The separation of skills into traditional vision tasks and higher-order skills suggests a progression in complexity, with the foundation model capable of performing both basic and advanced tasks. The diagram implies that the foundation model can learn from various data types, including visual, textual, and audio data, to develop a holistic understanding of the world. The model's ability to adapt and develop higher-order skills like theory of mind and commonsense reasoning suggests a potential for more sophisticated AI applications.