\n
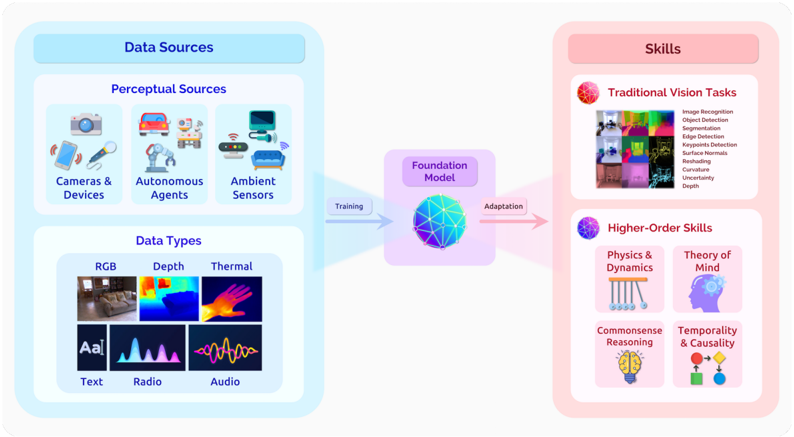
## Diagram: Foundation Model Data Flow
### Overview
This diagram illustrates the data sources and skills associated with a Foundation Model. It depicts a flow of information from various data sources (Perceptual Sources and Data Types) into the Foundation Model, and then the resulting skills that the model develops (Traditional Vision Tasks and Higher-Order Skills). The diagram is divided into three main sections: "Data Sources" (left), "Foundation Model" (center), and "Skills" (right).
### Components/Axes
The diagram consists of the following components:
* **Data Sources:** Divided into "Perceptual Sources" and "Data Types".
* **Perceptual Sources:** Includes icons representing Cameras & Devices, Autonomous Agents, and Ambient Sensors.
* **Data Types:** Includes images representing RGB, Depth, Thermal, Text, Radio, and Audio.
* **Foundation Model:** A central, stylized representation of a neural network.
* **Skills:** Divided into "Traditional Vision Tasks" and "Higher-Order Skills".
* **Traditional Vision Tasks:** A list of computer vision tasks.
* **Higher-Order Skills:** A list of more complex cognitive skills.
* **Arrows:** Indicate the flow of information from Data Sources to the Foundation Model ("Training") and from the Foundation Model to Skills ("Adaptation").
### Detailed Analysis or Content Details
**Data Sources - Perceptual Sources:**
* **Cameras & Devices:** Represented by a smartphone, a camera, and a tablet.
* **Autonomous Agents:** Represented by a robotic agent.
* **Ambient Sensors:** Represented by a smart home device (e.g., a smart speaker or thermostat).
**Data Sources - Data Types:**
* **RGB:** A standard color image.
* **Depth:** A depth map, showing distance from the sensor.
* **Thermal:** A thermal image, showing heat signatures.
* **Text:** Represented by the "Aal" label.
* **Radio:** A radio wave visualization.
* **Audio:** An audio waveform.
**Foundation Model:**
* The model is depicted as a complex network of interconnected nodes.
* An arrow labeled "Training" points from the Data Sources towards the Foundation Model.
* An arrow labeled "Adaptation" points from the Foundation Model towards the Skills.
**Skills - Traditional Vision Tasks:**
* Image Recognition
* Object Detection
* Segmentation
* Edge Detection
* Keypoints Detection
* Surface Normals
* Re-shading
* Curvature
* Uncertainty
* Depth
**Skills - Higher-Order Skills:**
* Physics & Dynamics
* Theory of Mind
* Commonsense Reasoning
* Temporality & Causality
### Key Observations
* The diagram emphasizes the multi-modal nature of the data used to train the Foundation Model, encompassing visual, textual, and auditory information.
* The distinction between "Training" and "Adaptation" suggests a two-stage process: initial learning from data sources, followed by refinement and application to specific skills.
* The skills are categorized into "Traditional Vision Tasks" and "Higher-Order Skills," indicating a progression from basic perception to more complex cognitive abilities.
### Interpretation
The diagram illustrates the concept of a Foundation Model as a central component capable of learning from diverse data sources and developing a wide range of skills. The model's ability to integrate information from different modalities (RGB, Depth, Text, Audio, etc.) is crucial for achieving both traditional computer vision tasks and more advanced cognitive abilities like physics reasoning and theory of mind. The "Training" and "Adaptation" arrows suggest that the model is not simply programmed with these skills, but rather learns them through exposure to data and subsequent refinement. The diagram highlights the potential of Foundation Models to bridge the gap between perception and cognition, enabling machines to understand and interact with the world in a more human-like way. The inclusion of "Uncertainty" as a traditional vision task suggests an awareness of the limitations of perception and the importance of quantifying confidence in predictions. The "Aal" label under text is unclear and may be a placeholder or an abbreviation.