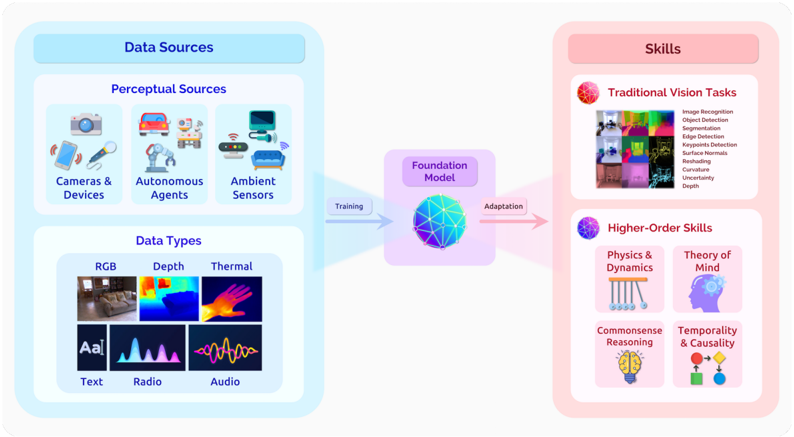
## Diagram: Foundation Model Pipeline for Multimodal Perception and Reasoning
### Overview
This diagram illustrates a conceptual pipeline for training a foundation model on diverse perceptual data to enable both traditional computer vision tasks and higher-order cognitive skills. The flow moves from left to right: data sources feed into a central foundation model, which is then adapted to perform various skills.
### Components/Axes
The diagram is organized into three primary vertical sections, connected by directional arrows.
**1. Left Section: Data Sources (Blue Container)**
* **Main Header:** "Data Sources"
* **Subsection 1: Perceptual Sources** (Top-left)
* Header: "Perceptual Sources"
* Contains three icon groups with labels:
1. **Cameras & Devices:** Icon of a camera, smartphone, and microphone.
2. **Autonomous Agents:** Icon of a car, robot arm, and delivery robot.
3. **Ambient Sensors:** Icon of a Wi-Fi router, security camera, and smart speaker.
* **Subsection 2: Data Types** (Bottom-left)
* Header: "Data Types"
* Contains a 2x3 grid of sample images/icons with labels:
1. **RGB:** A photograph of a living room.
2. **Depth:** A color-coded depth map of a hand.
3. **Thermal:** A thermal image of a hand.
4. **Text:** The letters "Aa".
5. **Radio:** A waveform graphic.
6. **Audio:** A different waveform graphic.
**2. Center Section: Foundation Model (Purple Container)**
* **Header:** "Foundation Model"
* **Central Icon:** A stylized, multi-faceted, blue and purple geometric sphere.
* **Process Arrows:**
* A blue arrow labeled "Training" points from the Data Sources section to the Foundation Model.
* A pink arrow labeled "Adaptation" points from the Foundation Model to the Skills section.
**3. Right Section: Skills (Pink Container)**
* **Main Header:** "Skills"
* **Subsection 1: Traditional Vision Tasks** (Top-right)
* Header: "Traditional Vision Tasks"
* Contains a collage of small example images (segmentation masks, depth maps, etc.) and a bulleted list:
* Image Recognition
* Object Detection
* Segmentation
* Image Generation
* Keypoints Detection
* Edge Detection
* Restoring
* Generation
* Uncertainty
* Depth
* **Subsection 2: Higher-Order Skills** (Bottom-right)
* Header: "Higher-Order Skills"
* Contains four icon groups with labels:
1. **Physics & Dynamics:** Icon of Newton's cradle.
2. **Theory of Mind:** Icon of a human head silhouette with gears inside.
3. **Commonsense Reasoning:** Icon of a brain with a lightbulb.
4. **Temporality & Causality:** Icon of a clock and interconnected nodes.
### Detailed Analysis
The diagram presents a clear, linear workflow:
1. **Input Stage:** Diverse data is collected from various perceptual sources (cameras, agents, sensors) and exists in multiple modalities (visual, depth, thermal, textual, radio, audio).
2. **Processing Stage:** This multimodal data is used for the "Training" of a central "Foundation Model," represented as a complex, integrated sphere.
3. **Output/Adaptation Stage:** The trained foundation model undergoes "Adaptation" to specialize in two broad categories of skills:
* **Traditional Vision Tasks:** A comprehensive list of standard computer vision problems, from recognition and detection to generation and restoration.
* **Higher-Order Skills:** More abstract, cognitive capabilities that involve understanding physical laws, mental states, everyday logic, and time-based relationships.
### Key Observations
* **Scope of Data:** The diagram emphasizes extreme multimodality, going beyond standard RGB images to include depth, thermal, text, radio signals, and audio.
* **Skill Hierarchy:** There is a clear distinction made between concrete, pixel-level "Traditional Vision Tasks" and abstract, reasoning-based "Higher-Order Skills."
* **Central Role of Foundation Model:** The foundation model is positioned as the crucial, unified processing hub that bridges raw sensory data and advanced cognitive abilities.
* **Visual Language:** The diagram uses color coding (blue for data, purple for model, pink for skills) and intuitive icons to make the complex pipeline accessible.
### Interpretation
This diagram argues for a paradigm in artificial intelligence where a single, large-scale foundation model, trained on a vast and heterogeneous corpus of perceptual data, can serve as a general-purpose backbone. The key insight is that such a model doesn't just perform isolated tasks; it develops a rich, internal representation of the world that can be efficiently *adapted* to solve both low-level perception problems (like finding edges in an image) and high-level reasoning challenges (like predicting physical interactions or understanding intent).
The pipeline suggests that higher-order intelligence (Theory of Mind, Causality) is not a separate system but an emergent capability that can be built upon the same foundational understanding derived from raw sensory experience. The "Adaptation" step is critical, implying that the foundation model provides a general capability that is then fine-tuned or prompted for specific applications, making the development of complex AI systems more modular and efficient. The inclusion of "Uncertainty" as a traditional task is notable, highlighting the importance of model confidence estimation in reliable AI systems.