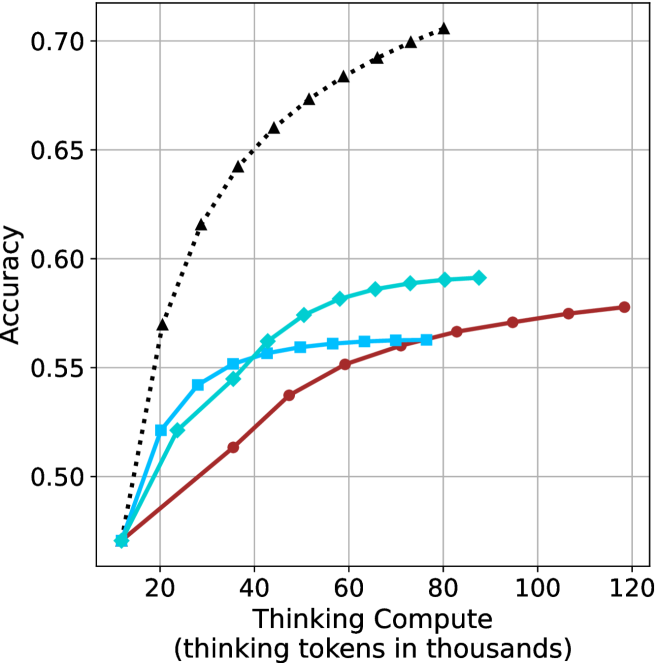
## Line Chart: Accuracy vs. Thinking Compute for Reasoning Methods
### Overview
The image is a line chart comparing the performance (accuracy) of four different AI reasoning methods as a function of computational resources ("Thinking Compute"). The chart demonstrates how each method's accuracy scales with an increasing budget of "thinking tokens."
### Components/Axes
* **Chart Type:** Multi-series line chart with markers.
* **X-Axis:**
* **Title:** `Thinking Compute (thinking tokens in thousands)`
* **Scale:** Linear, ranging from approximately 10 to 120 (representing 10,000 to 120,000 thinking tokens).
* **Major Tick Marks:** 20, 40, 60, 80, 100, 120.
* **Y-Axis:**
* **Title:** `Accuracy`
* **Scale:** Linear, ranging from approximately 0.47 to 0.71.
* **Major Tick Marks:** 0.50, 0.55, 0.60, 0.65, 0.70.
* **Legend:** Located in the top-left corner of the plot area. It contains four entries:
1. **Chain-of-Thought (CoT):** Black dotted line with upward-pointing triangle markers.
2. **Self-Consistency (SC):** Cyan (light blue) solid line with diamond markers.
3. **Tree of Thoughts (ToT):** Cyan (light blue) solid line with square markers.
4. **Reflexion:** Red solid line with circle markers.
* **Grid:** A light gray grid is present for both major x and y ticks.
### Detailed Analysis
**Data Series Trends and Approximate Points:**
1. **Chain-of-Thought (CoT) - Black Dotted Line, Triangle Markers:**
* **Trend:** Shows the steepest and most consistent upward slope, indicating the highest marginal gain in accuracy per additional thinking token. It does not appear to plateau within the displayed range.
* **Approximate Data Points:**
* (10, 0.47)
* (20, 0.57)
* (30, 0.615)
* (40, 0.64)
* (50, 0.66)
* (60, 0.68)
* (70, 0.69)
* (80, 0.705)
2. **Self-Consistency (SC) - Cyan Line, Diamond Markers:**
* **Trend:** Shows a strong initial increase that begins to decelerate (curve flattens) after approximately 40-50k tokens. It achieves the second-highest accuracy.
* **Approximate Data Points:**
* (10, 0.47)
* (20, 0.52)
* (30, 0.545)
* (40, 0.56)
* (50, 0.575)
* (60, 0.58)
* (70, 0.585)
* (80, 0.59)
3. **Tree of Thoughts (ToT) - Cyan Line, Square Markers:**
* **Trend:** Increases initially but plateaus relatively early, showing minimal gains after approximately 50-60k tokens. Its final accuracy is very close to that of the SC method at the same compute level (~60k tokens).
* **Approximate Data Points:**
* (10, 0.47)
* (20, 0.52)
* (30, 0.55)
* (40, 0.555)
* (50, 0.56)
* (60, 0.56)
* (70, 0.56)
4. **Reflexion - Red Line, Circle Markers:**
* **Trend:** Shows the most gradual, nearly linear increase. It starts at the same point as the others but is consistently outperformed by CoT and SC for most of the range. It continues to improve slowly even at high compute levels (120k tokens).
* **Approximate Data Points:**
* (10, 0.47)
* (20, 0.49)
* (30, 0.51)
* (40, 0.535)
* (50, 0.55)
* (60, 0.56)
* (70, 0.565)
* (80, 0.565)
* (90, 0.57)
* (100, 0.575)
* (110, 0.578)
* (120, 0.58)
### Key Observations
* **Common Starting Point:** All four methods begin at approximately the same accuracy (~0.47) with minimal compute (~10k tokens).
* **Performance Hierarchy:** For nearly all compute budgets above 20k tokens, the performance order is consistent: CoT > SC ≈ ToT > Reflexion. The gap between CoT and the others widens significantly as compute increases.
* **Diminishing Returns:** SC and ToT exhibit clear diminishing returns (plateauing), while CoT shows sustained strong returns. Reflexion shows very slow but steady returns.
* **Convergence:** The SC (diamond) and ToT (square) lines converge around 60k tokens at an accuracy of ~0.56.
### Interpretation
This chart provides a comparative efficiency analysis of different AI reasoning strategies. The data suggests that the **Chain-of-Thought (CoT)** method is the most "compute-efficient" for scaling accuracy; it translates additional thinking tokens into performance gains most effectively within the tested range. This could imply its underlying process is better structured to utilize extended deliberation.
**Self-Consistency (SC)** and **Tree of Thoughts (ToT)** offer a middle ground, providing better accuracy than basic CoT at lower compute budgets but hitting a performance ceiling sooner. Their similar trajectories suggest they may share fundamental limitations in how they explore the solution space.
**Reflexion**, while improving steadily, is the least efficient in this context. Its linear growth might indicate a more iterative, less parallelizable process that benefits from more tokens but at a lower rate.
The key takeaway is that the choice of reasoning method has a profound impact on the return-on-investment for computational resources (thinking tokens). For tasks where high accuracy is critical and compute is available, CoT appears superior. For resource-constrained environments, SC or ToT might offer a better accuracy/compute trade-off at lower budgets. The chart does not show an upper bound for CoT, leaving open the question of where its performance might eventually plateau.