\n
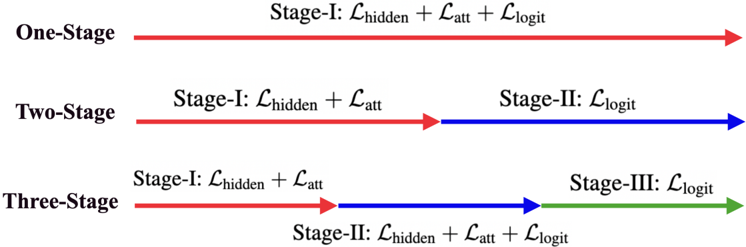
## Diagram: Training Stage Configurations with Loss Functions
### Overview
The image is a technical diagram illustrating three different training stage configurations for a machine learning model, likely in the context of multi-task or curriculum learning. It visually compares how loss functions are distributed across one, two, or three sequential training stages. The diagram uses colored arrows and text labels to denote the stages and the specific loss components applied at each.
### Components/Axes
The diagram is organized into three horizontal rows, each representing a distinct configuration:
1. **Top Row (One-Stage):** A single, continuous red arrow pointing right.
2. **Middle Row (Two-Stage):** A red arrow segment followed by a blue arrow segment, pointing right.
3. **Bottom Row (Three-Stage):** A red arrow segment, followed by a blue arrow segment, followed by a green arrow segment, all pointing right.
**Text Labels and Loss Functions:**
* **Configuration Labels (Left-aligned):** "One-Stage", "Two-Stage", "Three-Stage".
* **Stage Labels (Positioned above/below arrows):** "Stage-I", "Stage-II", "Stage-III".
* **Loss Function Notation:** The diagram uses the script letter `ℒ` (L) to denote loss functions, with subscripts indicating the type:
* `ℒ_hidden`: Hidden state loss.
* `ℒ_att`: Attention loss.
* `ℒ_logit`: Logit (output) loss.
* **Arrow Colors:** Red, Blue, and Green are used to visually distinguish the sequential stages within each configuration.
### Detailed Analysis
The diagram details the composition of each training stage for the three configurations:
**1. One-Stage Configuration:**
* **Visual Flow:** A single, unbroken red arrow spans the entire width.
* **Stage & Loss:** The entire process is labeled "Stage-I" and applies a combined loss: `ℒ_hidden + ℒ_att + ℒ_logit`.
**2. Two-Stage Configuration:**
* **Visual Flow:** The process is split into two sequential segments.
* **First Segment (Red Arrow):** Labeled "Stage-I". Applies the loss: `ℒ_hidden + ℒ_att`.
* **Second Segment (Blue Arrow):** Labeled "Stage-II". Applies the loss: `ℒ_logit`.
**3. Three-Stage Configuration:**
* **Visual Flow:** The process is split into three sequential segments.
* **First Segment (Red Arrow):** Labeled "Stage-I". Applies the loss: `ℒ_hidden + ℒ_att`.
* **Second Segment (Blue Arrow):** Labeled "Stage-II". Applies the loss: `ℒ_hidden + ℒ_att + ℒ_logit`.
* **Third Segment (Green Arrow):** Labeled "Stage-III". Applies the loss: `ℒ_logit`.
### Key Observations
* **Progressive Decomposition:** The configurations show a progression from a monolithic training approach (One-Stage) to increasingly decomposed, multi-stage approaches.
* **Loss Function Distribution:** The `ℒ_logit` loss is isolated in the final stage for the Two-Stage and Three-Stage configurations. In the Three-Stage setup, `ℒ_logit` is reintroduced in Stage-II alongside the other losses before being isolated again in Stage-III.
* **Consistent Initial Stage:** Stage-I is identical in both the Two-Stage and Three-Stage configurations, focusing only on `ℒ_hidden` and `ℒ_att`.
* **Color-Coded Sequencing:** The consistent use of red for Stage-I, blue for Stage-II, and green for Stage-III across the rows provides a clear visual anchor for comparing the stage boundaries.
### Interpretation
This diagram likely illustrates different strategies for training a complex model, such as a neural network for language or vision tasks. The loss components suggest a model with hidden representations, an attention mechanism, and a final classification/output layer (logits).
* **One-Stage:** Represents standard, end-to-end training where all model components are optimized simultaneously against all objectives from the start. This is simple but may lead to competition between loss signals.
* **Two-Stage:** Represents a form of **curriculum learning** or **staged fine-tuning**. The model first learns foundational features (hidden states and attention) without the pressure of final classification (`ℒ_logit`). Once these are stable, it focuses solely on optimizing the output layer. This can stabilize training and improve final performance.
* **Three-Stage:** Represents a more nuanced, possibly **iterative refinement** strategy. After the initial feature learning (Stage-I), the model undergoes a joint training phase (Stage-II) where all losses are active again, potentially to align the newly learned features with the final objective. Finally, it performs a dedicated refinement of the output layer (Stage-III). This could be beneficial for very complex tasks or models where feature-objective alignment is critical.
The diagram effectively communicates that there is no single "correct" way to structure training; the choice depends on the model's complexity, the nature of the loss functions, and the desired training dynamics. The Three-Stage approach, while more complex, offers the most granular control over the optimization process.