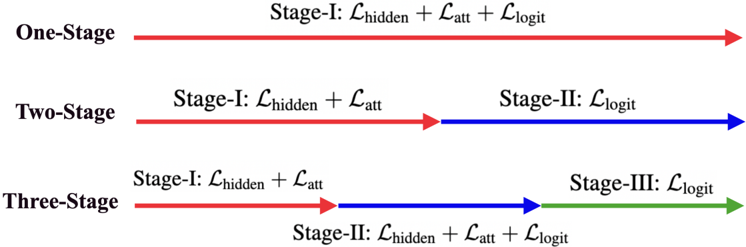
## Diagram: Multi-Stage Model Training Pipeline
### Overview
The diagram illustrates a comparative analysis of three model training approaches (One-Stage, Two-Stage, Three-Stage) using colored horizontal lines to represent progression through training stages. Each line is segmented into phases labeled with loss function combinations (L_hidden, L_att, L_logit), connected by arrows indicating sequential dependencies.
### Components/Axes
- **Vertical Axis**: Model complexity tiers (One-Stage, Two-Stage, Three-Stage)
- **Horizontal Segments**: Training stages (Stage-I, Stage-II, Stage-III)
- **Color Coding**:
- Red: One-Stage model
- Blue: Two-Stage model
- Green: Three-Stage model
- **Loss Functions**:
- L_hidden (Hidden layer loss)
- L_att (Attention mechanism loss)
- L_logit (Logit prediction loss)
### Detailed Analysis
1. **One-Stage Model (Red Line)**:
- Single-phase training (Stage-I)
- Combines all three loss functions:
`L_hidden + L_att + L_logit`
2. **Two-Stage Model (Blue Line)**:
- Stage-I: `L_hidden + L_att`
(Focus on feature extraction and attention)
- Stage-II: `L_logit`
(Final prediction optimization)
3. **Three-Stage Model (Green Line)**:
- Stage-I: `L_hidden + L_att`
(Initial feature and attention training)
- Stage-II: `L_hidden + L_att + L_logit`
(Integrated optimization of all components)
- Stage-III: `L_logit`
(Specialized logit refinement)
### Key Observations
- **Loss Function Progression**:
- One-Stage: All losses applied simultaneously
- Two-Stage: Early-stage specialization (L_hidden + L_att) followed by logit focus
- Three-Stage: Gradual complexity increase with staged logit emphasis
- **Arrow Flow**:
- Red/Blue arrows (Stage-I → Stage-II) indicate sequential training
- Green arrow (Stage-II → Stage-III) shows final refinement phase
- **Color Consistency**:
- All Stage-I segments use red/blue/green arrows matching model tiers
- Stage-II blue arrows align with Two-Stage model
- Stage-III green arrow matches Three-Stage model
### Interpretation
This diagram demonstrates a pedagogical framework for model training complexity:
1. **One-Stage** represents brute-force optimization with concurrent loss minimization
2. **Two-Stage** introduces modular training, separating feature/attention learning from final prediction
3. **Three-Stage** adds a refinement phase, suggesting iterative improvement of logit predictions after foundational training
The staged approach implies:
- **Pedagogical Analogy**: Early stages act as "foundation" training, later stages as "specialization"
- **Computational Tradeoff**: More stages may increase training time but potentially improve convergence
- **Loss Function Hierarchy**: L_logit receives increasing emphasis in later stages, suggesting its critical role in final performance
No numerical values are present - the diagram focuses on architectural relationships rather than quantitative metrics.