\n
## Line Chart: Reinforcement Learning Reward Curves
### Overview
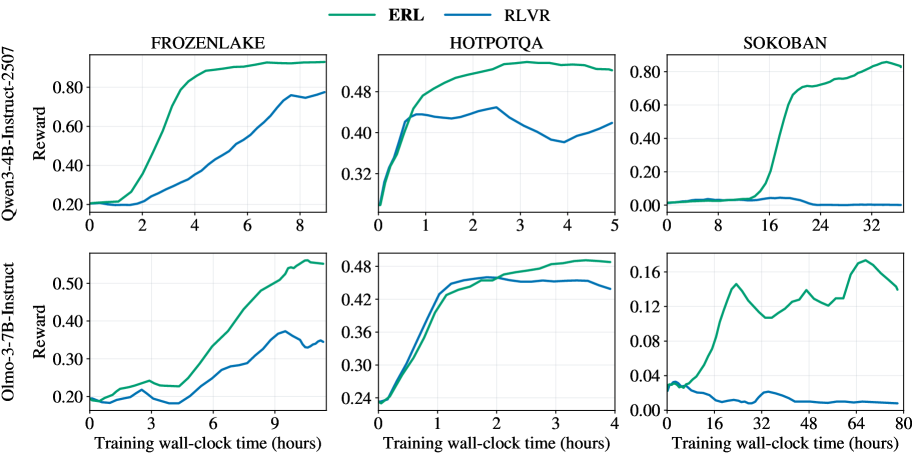
The image presents six line charts displaying reward curves for two reinforcement learning algorithms, ERL (green) and RLVR (blue), across three different environments: FrozenLake, HotpotQA, and Sokoban. Each environment is evaluated using two language models: Owen-3-4B-Instruct-2.507 and Olmo-3-7B-Instruct. The x-axis represents training wall-clock time in hours, and the y-axis represents the reward.
### Components/Axes
* **X-axis Label (all charts):** "Training wall-clock time (hours)"
* **Y-axis Label (top row):** "Reward" (for Owen-3-4B-Instruct-2.507)
* **Y-axis Label (bottom row):** "Reward" (for Olmo-3-7B-Instruct)
* **Legend (top-left of each chart):**
* Green Line: "ERL"
* Blue Line: "RLVR"
* **Chart Titles (top of each chart):**
* "FROZENLAKE"
* "HOTPOTQA"
* "SOKOBAN"
* **Model Labels (left side of each 2x3 grid):**
* "Owen-3-4B-Instruct-2.507"
* "Olmo-3-7B-Instruct"
* **Y-axis Scale (approximate):**
* FrozenLake (Owen): 0.20 to 0.80
* HotpotQA (Owen): 0.32 to 0.48
* Sokoban (Owen): 0.00 to 0.80
* FrozenLake (Olmo): 0.20 to 0.50
* HotpotQA (Olmo): 0.24 to 0.48
* Sokoban (Olmo): 0.04 to 0.16
### Detailed Analysis or Content Details
**1. FrozenLake (Owen-3-4B-Instruct-2.507):**
* ERL (Green): Starts at approximately 0.22, increases rapidly to around 0.75 by 6 hours, and plateaus around 0.80.
* RLVR (Blue): Starts at approximately 0.25, increases to around 0.45 by 4 hours, then fluctuates between 0.40 and 0.50, ending around 0.48.
**2. HotpotQA (Owen-3-4B-Instruct-2.507):**
* ERL (Green): Starts at approximately 0.35, increases steadily to around 0.47 by 3 hours, and remains relatively stable around 0.48.
* RLVR (Blue): Starts at approximately 0.40, initially decreases slightly, then increases to around 0.45 by 2 hours, and fluctuates between 0.40 and 0.44, ending around 0.42.
**3. Sokoban (Owen-3-4B-Instruct-2.507):**
* ERL (Green): Starts at approximately 0.20, increases steadily to around 0.60 by 16 hours, and fluctuates between 0.50 and 0.80.
* RLVR (Blue): Starts at approximately 0.20, increases slowly to around 0.30 by 16 hours, and fluctuates between 0.20 and 0.40, ending around 0.30.
**4. FrozenLake (Olmo-3-7B-Instruct):**
* ERL (Green): Starts at approximately 0.22, increases rapidly to around 0.45 by 6 hours, and plateaus around 0.50.
* RLVR (Blue): Starts at approximately 0.25, increases to around 0.35 by 4 hours, and remains relatively stable around 0.30.
**5. HotpotQA (Olmo-3-7B-Instruct):**
* ERL (Green): Starts at approximately 0.25, increases steadily to around 0.45 by 3 hours, and remains relatively stable around 0.46.
* RLVR (Blue): Starts at approximately 0.28, increases to around 0.35 by 2 hours, and fluctuates between 0.30 and 0.35, ending around 0.32.
**6. Sokoban (Olmo-3-7B-Instruct):**
* ERL (Green): Starts at approximately 0.04, increases slowly to around 0.12 by 32 hours, and fluctuates between 0.08 and 0.16.
* RLVR (Blue): Starts at approximately 0.04, increases slowly to around 0.08 by 32 hours, and remains relatively stable around 0.06.
### Key Observations
* ERL consistently outperforms RLVR across all environments and language models.
* The reward curves for FrozenLake and HotpotQA reach a plateau relatively quickly, while Sokoban shows more prolonged learning and fluctuation.
* The Olmo-3-7B-Instruct model generally yields lower rewards compared to Owen-3-4B-Instruct-2.507, particularly in the Sokoban environment.
* Sokoban consistently has the lowest reward values across all configurations.
### Interpretation
The data suggests that ERL is a more effective reinforcement learning algorithm than RLVR for the tested environments and language models. The differences in performance are particularly pronounced in the Sokoban environment, indicating that ERL may be better suited for more complex tasks. The lower rewards obtained with the Olmo-3-7B-Instruct model could be due to its different architecture or training data, potentially impacting its ability to learn optimal policies. The plateauing of reward curves in FrozenLake and HotpotQA suggests that the algorithms converge relatively quickly in these environments, while the continued fluctuation in Sokoban indicates that further training or algorithm adjustments may be needed to achieve optimal performance. The Sokoban environment appears to be the most challenging, requiring significantly more training time to achieve even modest rewards.