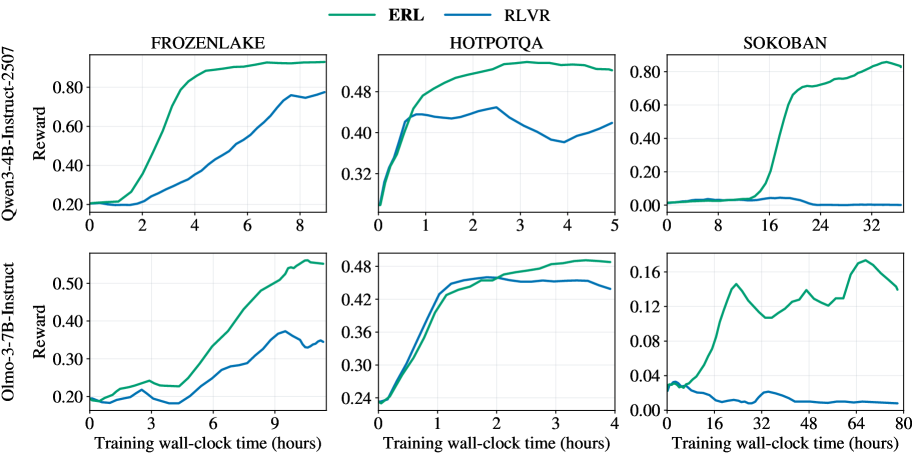
## Line Graphs: Algorithm Performance Comparison Across Environments
### Overview
The image contains six line graphs comparing the performance of two algorithms, **ERL** (green) and **RLVR** (blue), across three environments: **FROZENLAKE**, **HOTPOTQA**, and **SOKOBAN**. Each environment is evaluated for two models: **Qwen3-4B-Instruct-2507** (top row) and **Olmo-3-7B-Instruct** (bottom row). The x-axis represents training wall-clock time (hours), and the y-axis represents reward values.
---
### Components/Axes
- **Legends**:
- **ERL**: Green line (top-left corner of all graphs).
- **RLVR**: Blue line (top-left corner of all graphs).
- **Axes**:
- **X-axis**: "Training wall-clock time (hours)" (ranges: 0–8 for Qwen3-4B, 0–4 for Olmo-3-7B, 0–80 for SOKOBAN).
- **Y-axis**: "Reward" (scales vary by environment: 0–0.8 for Qwen3-4B, 0–0.5 for Olmo-3-7B, 0–0.16 for SOKOBAN).
- **Graph Titles**:
- Top row: "FROZENLAKE", "HOTPOTQA", "SOKOBAN" (Qwen3-4B-Instruct-2507).
- Bottom row: "FROZENLAKE", "HOTPOTQA", "SOKOBAN" (Olmo-3-7B-Instruct).
---
### Detailed Analysis
#### FROZENLAKE (Qwen3-4B-Instruct-2507)
- **ERL**: Starts at ~0.2, rises steadily to ~0.85 by 8 hours.
- **RLVR**: Starts at ~0.2, increases gradually to ~0.6 by 8 hours.
- **Trend**: ERL outperforms RLVR consistently, with a steeper ascent.
#### HOTPOTQA (Qwen3-4B-Instruct-2507)
- **ERL**: Begins at ~0.3, peaks at ~0.8 by 4 hours, then plateaus.
- **RLVR**: Starts at ~0.3, fluctuates (dips to ~0.35 at 3 hours), stabilizes at ~0.4 by 4 hours.
- **Trend**: ERL dominates early, but RLVR shows volatility.
#### SOKOBAN (Qwen3-4B-Instruct-2507)
- **ERL**: Starts near 0, surges to ~0.8 after 32 hours.
- **RLVR**: Remains flat near 0 throughout.
- **Trend**: ERL achieves significant performance gain late in training; RLVR stagnates.
#### FROZENLAKE (Olmo-3-7B-Instruct)
- **ERL**: Starts at ~0.2, rises to ~0.5 by 9 hours.
- **RLVR**: Starts at ~0.2, increases to ~0.35 by 9 hours.
- **Trend**: ERL maintains a lead, but both models show slower progress than Qwen3-4B.
#### HOTPOTQA (Olmo-3-7B-Instruct)
- **ERL**: Begins at ~0.3, peaks at ~0.45 by 3 hours, then stabilizes.
- **RLVR**: Starts at ~0.3, rises to ~0.4 by 3 hours, then plateaus.
- **Trend**: ERL and RLVR converge, with ERL slightly ahead.
#### SOKOBAN (Olmo-3-7B-Instruct)
- **ERL**: Starts near 0, peaks at ~0.12 at 48 hours, then drops to ~0.08.
- **RLVR**: Remains near 0 throughout.
- **Trend**: ERL shows a delayed peak with a post-peak decline; RLVR stagnates.
---
### Key Observations
1. **ERL Dominance**: ERL consistently outperforms RLVR in all environments and models, except HOTPOTQA (Olmo-3-7B), where performance is closer.
2. **SOKOBAN Anomaly**: ERL’s sharp rise in SOKOBAN (Qwen3-4B) suggests delayed but significant learning, while RLVR fails to adapt.
3. **Model Size Impact**: Qwen3-4B (larger model) achieves higher rewards than Olmo-3-7B (smaller model) across all environments.
4. **Training Efficiency**: ERL reaches higher rewards faster in FROZENLAKE and HOTPOTQA, while SOKOBAN requires extended training (80 hours) for ERL to stabilize.
---
### Interpretation
- **Algorithm Effectiveness**: ERL’s architecture or training strategy enables faster and more robust learning across diverse tasks (navigation, question-answering, puzzle-solving).
- **Model Capacity**: Larger models (Qwen3-4B) leverage ERL’s advantages more effectively, achieving higher rewards than smaller models (Olmo-3-7B).
- **SOKOBAN Challenges**: The delayed performance peak in SOKOBAN (ERL) implies complex task dynamics requiring prolonged training. RLVR’s stagnation suggests it struggles with sparse reward structures.
- **Anomalies**: The dip in ERL’s HOTPOTQA (Qwen3-4B) at 3 hours may indicate overfitting or temporary instability, but recovery suggests resilience.
This analysis highlights ERL’s superiority in sample efficiency and task adaptability, with implications for deploying RL algorithms in real-world scenarios requiring rapid learning.