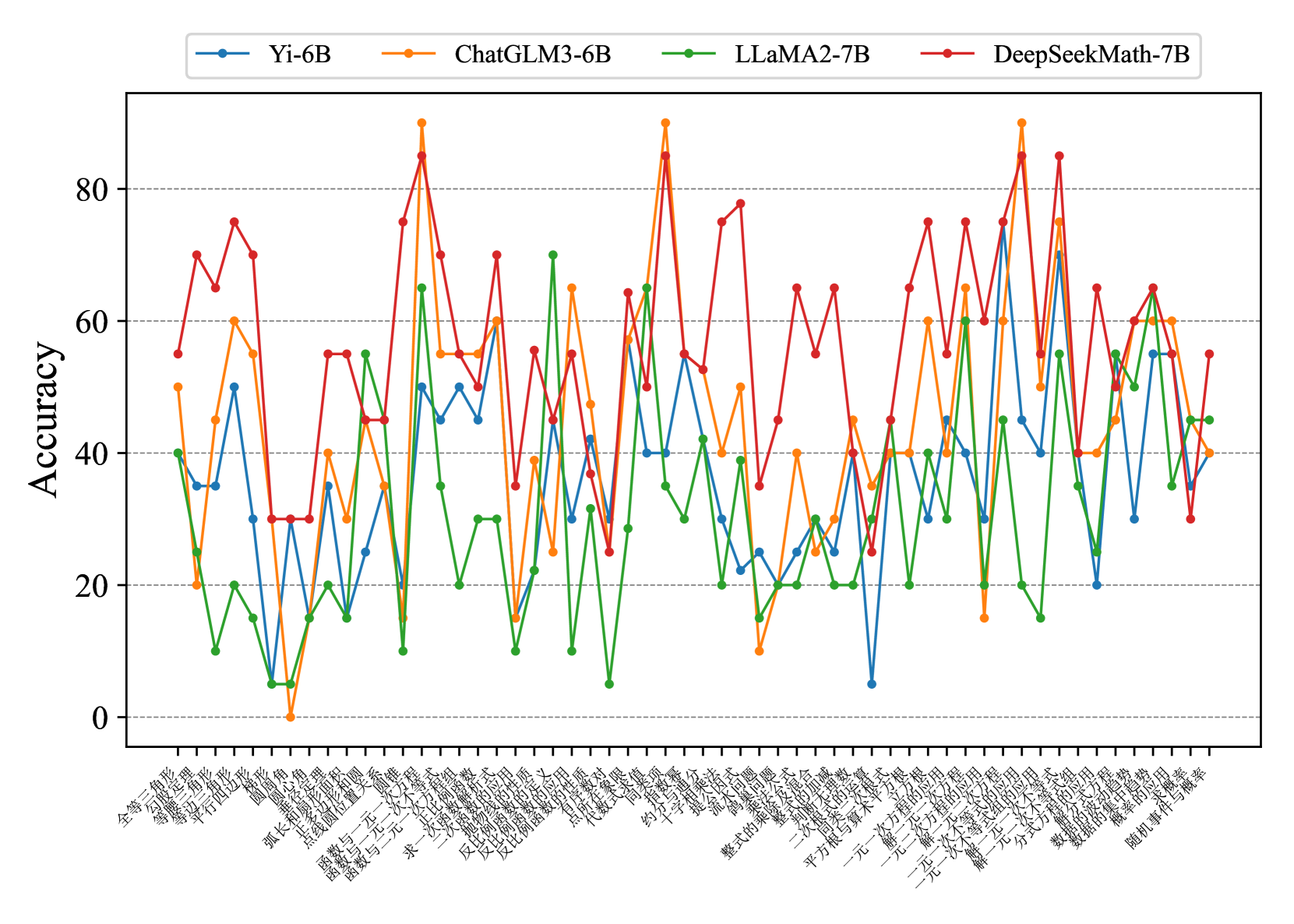
## Line Chart: Model Accuracy on Math Problems
### Overview
This line chart compares the accuracy of four different language models (Yi-6B, ChatGLM3-6B, LLaMA2-7B, and DeepSeekMath-7B) across a series of math problems. The x-axis represents the math problem categories, and the y-axis represents the accuracy score, ranging from 0 to 80.
### Components/Axes
* **Y-axis Title:** Accuracy
* **X-axis Labels:** The x-axis labels are in Chinese characters. A rough translation (using online tools) suggests they represent different categories of math problems, including:
* 全面提升 (Comprehensive Improvement)
* 数学应用 (Math Application)
* 初中数学 (Junior High Math)
* 高等数学 (Higher Math)
* 微积分 (Calculus)
* 线性代数 (Linear Algebra)
* 概率统计 (Probability and Statistics)
* 复分析 (Complex Analysis)
* 多元微积分 (Multivariable Calculus)
* 一元微积分 (Single Variable Calculus)
* 几何 (Geometry)
* 微积分应用 (Calculus Application)
* 因果推理 (Causal Reasoning)
* 随机过程 (Stochastic Processes)
* 随机事件概率 (Probability of Random Events)
* **Legend:** Located at the top of the chart, the legend identifies each line by model name and color:
* Yi-6B (Light Blue)
* ChatGLM3-6B (Orange)
* LLaMA2-7B (Green)
* DeepSeekMath-7B (Red)
### Detailed Analysis
The chart displays accuracy as a function of problem category. I will describe each line's trend and then extract approximate data points.
* **Yi-6B (Light Blue):** This line fluctuates significantly, starting around 40, peaking around 70, and then dropping to around 20 before rising again.
* 全面提升: ~42
* 数学应用: ~50
* 初中数学: ~65
* 高等数学: ~55
* 微积分: ~45
* 线性代数: ~30
* 概率统计: ~25
* 复分析: ~35
* 多元微积分: ~40
* 一元微积分: ~50
* 几何: ~45
* 微积分应用: ~60
* 因果推理: ~50
* 随机过程: ~30
* 随机事件概率: ~40
* **ChatGLM3-6B (Orange):** This line generally shows higher accuracy than Yi-6B, with peaks around 85 and a more stable performance.
* 全面提升: ~60
* 数学应用: ~70
* 初中数学: ~85
* 高等数学: ~75
* 微积分: ~65
* 线性代数: ~50
* 概率统计: ~40
* 复分析: ~55
* 多元微积分: ~60
* 一元微积分: ~70
* 几何: ~65
* 微积分应用: ~80
* 因果推理: ~70
* 随机过程: ~50
* 随机事件概率: ~60
* **LLaMA2-7B (Green):** This line consistently shows the lowest accuracy, generally below 30, with minimal fluctuation.
* 全面提升: ~10
* 数学应用: ~15
* 初中数学: ~20
* 高等数学: ~15
* 微积分: ~10
* 线性代数: ~10
* 概率统计: ~15
* 复分析: ~20
* 多元微积分: ~15
* 一元微积分: ~20
* 几何: ~15
* 微积分应用: ~25
* 因果推理: ~15
* 随机过程: ~10
* 随机事件概率: ~15
* **DeepSeekMath-7B (Red):** This line exhibits the highest accuracy overall, with peaks exceeding 80 and generally stable performance.
* 全面提升: ~50
* 数学应用: ~75
* 初中数学: ~85
* 高等数学: ~80
* 微积分: ~70
* 线性代数: ~60
* 概率统计: ~50
* 复分析: ~65
* 多元微积分: ~70
* 一元微积分: ~75
* 几何: ~70
* 微积分应用: ~85
* 因果推理: ~75
* 随机过程: ~60
* 随机事件概率: ~70
### Key Observations
* DeepSeekMath-7B consistently outperforms the other models across all problem categories.
* LLaMA2-7B consistently performs the worst.
* ChatGLM3-6B generally performs better than Yi-6B, but with more variability.
* The accuracy scores vary significantly depending on the problem category. "初中数学" (Junior High Math) and "微积分应用" (Calculus Application) seem to be categories where the models achieve higher accuracy.
### Interpretation
The data suggests that DeepSeekMath-7B is the most capable model for solving the presented math problems, while LLaMA2-7B struggles significantly. The varying accuracy across different problem categories indicates that the models' strengths and weaknesses are problem-specific. The higher accuracy on "初中数学" and "微积分应用" might be due to these problems being more common in the training data or being inherently simpler. The chart highlights the importance of model selection based on the specific task and the need for further research to improve the performance of language models on complex math problems. The Chinese labels suggest the evaluation dataset is tailored towards a Chinese-speaking audience or curriculum. The large differences in performance between the models suggest that the architecture and training data play a significant role in mathematical reasoning capabilities.