\n
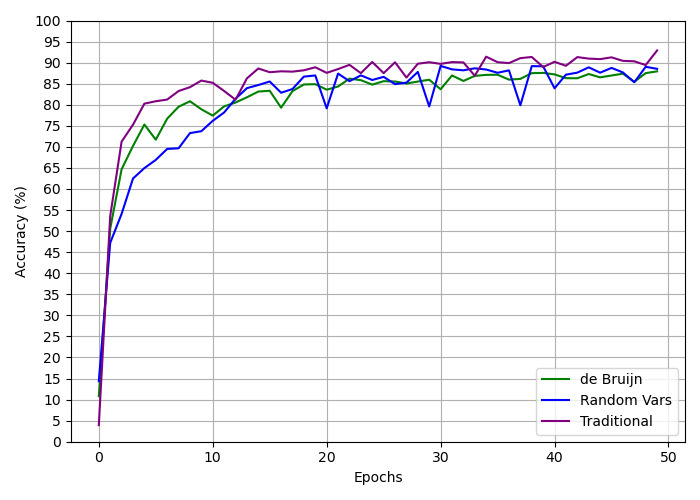
## Line Chart: Accuracy vs. Epochs for Different Methods
### Overview
This image presents a line chart comparing the accuracy of three different methods ("de Bruijn", "Random Vars", and "Traditional") over 50 epochs. The y-axis represents accuracy in percentage, while the x-axis represents the number of epochs. The chart visually demonstrates how the accuracy of each method evolves during the training process.
### Components/Axes
* **X-axis:** "Epochs" ranging from 0 to 50.
* **Y-axis:** "Accuracy (%)" ranging from 0 to 100.
* **Legend:** Located in the bottom-right corner, identifying the three data series:
* "de Bruijn" - Green line
* "Random Vars" - Blue line
* "Traditional" - Purple line
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
Let's analyze each line individually, noting trends and approximate data points.
* **de Bruijn (Green Line):** This line starts at approximately 10% accuracy at epoch 0 and rapidly increases to around 75% by epoch 5. It then plateaus, fluctuating between approximately 82% and 87% for the remainder of the epochs (5-50). At epoch 50, the accuracy is approximately 85%.
* **Random Vars (Blue Line):** This line also starts at approximately 10% accuracy at epoch 0 and shows a rapid increase, reaching around 80% by epoch 5. It then exhibits a more gradual increase, reaching a peak of approximately 90% around epoch 15-20. After this peak, it fluctuates between approximately 85% and 90% for the remaining epochs. At epoch 50, the accuracy is approximately 87%.
* **Traditional (Purple Line):** This line begins at approximately 10% accuracy at epoch 0 and increases steadily, reaching around 85% by epoch 5. It then plateaus, remaining relatively stable between approximately 88% and 93% for the rest of the epochs. At epoch 50, the accuracy is approximately 91%.
### Key Observations
* All three methods start with similar low accuracy.
* The "Traditional" method consistently achieves the highest accuracy throughout the training process.
* The "Random Vars" method shows the most significant initial increase in accuracy, but its performance plateaus earlier than the "Traditional" method.
* The "de Bruijn" method has the slowest initial increase and the lowest overall accuracy, but it still reaches a respectable level of performance.
* All three methods appear to converge in accuracy after approximately 20 epochs.
### Interpretation
The data suggests that the "Traditional" method is the most effective for this particular task, consistently achieving the highest accuracy. The "Random Vars" method demonstrates a rapid initial learning phase, but its performance plateaus relatively quickly. The "de Bruijn" method, while slower to learn, still achieves a reasonable level of accuracy. The convergence of the lines after 20 epochs indicates that further training may not yield significant improvements in accuracy for any of the methods. This could be due to the model reaching its capacity or the data being sufficiently learned. The initial rapid increase in all lines suggests that the models are quickly adapting to the initial patterns in the data. The subsequent plateau suggests diminishing returns from further training. The differences in peak accuracy and plateau levels highlight the varying effectiveness of each method in capturing the underlying complexities of the data.