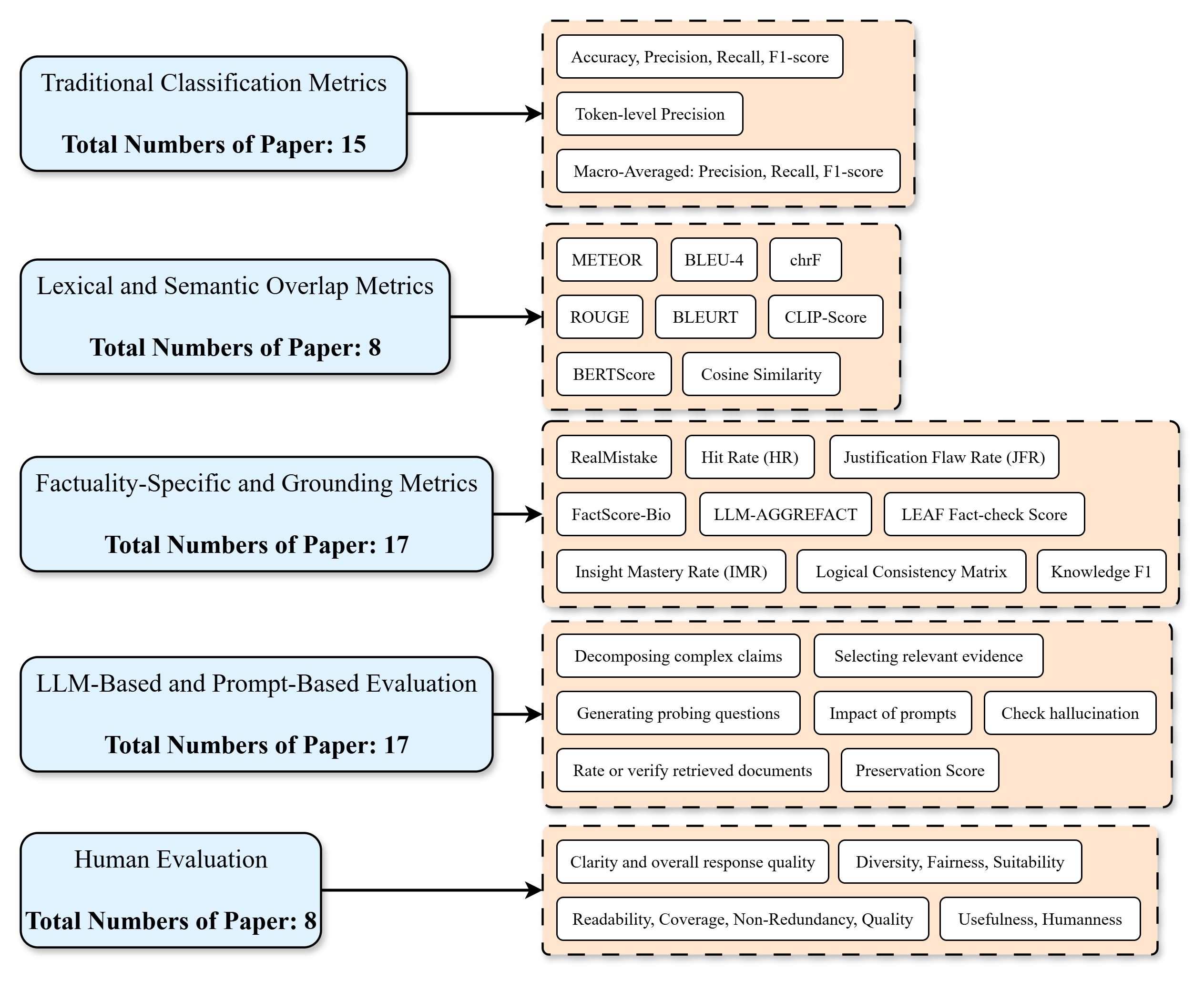
## Flowchart: Taxonomy of NLP Evaluation Metrics
### Overview
The flowchart categorizes evaluation metrics used in Natural Language Processing (NLP) research, organized into five primary categories with associated metrics and paper counts. Arrows connect categories to their respective metrics, creating a hierarchical structure.
### Components/Axes
- **Left Side (Categories)**:
- Traditional Classification Metrics (15 papers)
- Lexical and Semantic Overlap Metrics (8 papers)
- Factuality-Specific and Grounding Metrics (17 papers)
- LLM-Based and Prompt-Based Evaluation (17 papers)
- Human Evaluation (8 papers)
- **Right Side (Metrics)**:
- Grouped into four sections with subcategories:
1. **Traditional Classification Metrics**: Accuracy, Precision, Recall, F1-score, Token-level Precision, Macro-Averaged metrics.
2. **Lexical/Semantic Overlap**: METEOR, BLEU-4, chrF, ROUGE, BLEURT, CLIP-Score, BERTScore, Cosine Similarity.
3. **Factuality/Grounding**: RealMistake, Hit Rate (HR), Justification Flaw Rate (JFR), FactScore-Bio, LLM-AGGREFACT, LEAFFact-check Score, Insight Mastery Rate (IMR), Logical Consistency Matrix, Knowledge F1.
4. **LLM/Prompt-Based**: Decomposing complex claims, Selecting relevant evidence, Generating probing questions, Impact of prompts, Check hallucination, Rate/verify retrieved documents, Preservation Score.
5. **Human Evaluation**: Clarity/response quality, Diversity/Fairness/Suitability, Readability/Coverage/Non-Redundancy/Quality, Usefulness/Humanness.
### Detailed Analysis
- **Traditional Classification Metrics** (15 papers):
- Core metrics: Accuracy, Precision, Recall, F1-score.
- Token-level Precision and Macro-Averaged variants included.
- **Lexical/Semantic Overlap** (8 papers):
- Focus on string similarity (BLEU-4, chrF) and embedding-based metrics (BERTScore, Cosine Similarity).
- **Factuality/Grounding** (17 papers):
- Emphasis on factual correctness (FactScore-Bio, LLM-AGGREFACT) and justification quality (JFR, IMR).
- **LLM/Prompt-Based** (17 papers):
- Highlights evaluation of reasoning (decomposing claims) and prompt engineering (impact of prompts).
- **Human Evaluation** (8 papers):
- Subjective metrics like clarity, diversity, and human-like responses.
### Key Observations
1. **Research Focus**: Factuality/Grounding and LLM/Prompt-Based metrics dominate with 17 papers each, suggesting growing interest in these areas.
2. **Metric Diversity**: Lexical/Semantic Overlap and Human Evaluation have fewer papers (8 each), indicating niche or complementary roles.
3. **Hierarchical Structure**: Metrics are grouped by evaluation focus (e.g., factuality vs. lexical overlap), reflecting methodological priorities.
### Interpretation
This flowchart illustrates the evolution of NLP evaluation paradigms:
- **Traditional Metrics** (Accuracy, F1-score) remain foundational but are supplemented by newer approaches.
- **Factuality/Grounding** and **LLM/Prompt-Based** metrics dominate, aligning with trends in fact-checking and large language model evaluation.
- **Human Evaluation** is less represented (8 papers), possibly due to subjectivity or resource constraints.
- The taxonomy reveals a shift toward evaluating **reasoning** (LLM/Prompt-Based) and **factual accuracy**, critical for real-world NLP applications. The absence of a "None" category suggests all papers adopt at least one evaluation framework.