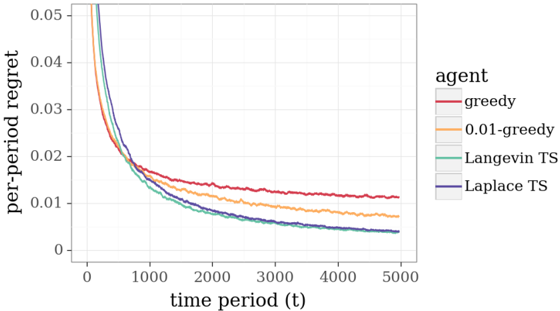
## Line Graph: Per-Period Regret Over Time for Different Agents
### Overview
The image is a line graph depicting the per-period regret of four different agents over time. The x-axis represents time periods (t) ranging from 0 to 5000, while the y-axis shows per-period regret values from 0 to 0.05. Four distinct lines represent the agents: "greedy" (red), "0.01-greedy" (orange), "Langevin TS" (teal), and "Laplace TS" (blue). All lines exhibit a decreasing trend, with varying rates of decline.
### Components/Axes
- **X-axis**: "time period (t)" with values from 0 to 5000.
- **Y-axis**: "per-period regret" with values from 0 to 0.05.
- **Legend**: Located on the right side of the graph, with the following mappings:
- Red: greedy
- Orange: 0.01-greedy
- Teal: Langevin TS
- Blue: Laplace TS
### Detailed Analysis
- **Greedy (Red Line)**:
- Starts at approximately 0.05 at t=0.
- Declines sharply to ~0.02 by t=1000.
- Flattens to ~0.01 by t=5000.
- **0.01-greedy (Orange Line)**:
- Starts slightly below the greedy line at ~0.045 at t=0.
- Declines more gradually, reaching ~0.01 by t=5000.
- **Langevin TS (Teal Line)**:
- Starts at ~0.045 at t=0.
- Declines to ~0.01 by t=5000, with a moderate slope.
- **Laplace TS (Blue Line)**:
- Starts at ~0.045 at t=0.
- Declines to ~0.01 by t=5000, with a slightly steeper slope than Langevin TS.
### Key Observations
1. **Initial Regret**: All agents begin with high regret (~0.045–0.05), but the greedy agent has the highest initial value.
2. **Rate of Improvement**:
- The greedy agent shows the steepest initial decline but flattens out.
- The 0.01-greedy agent has the slowest improvement, maintaining higher regret longer.
- The TS agents (Langevin and Laplace) exhibit intermediate performance, with Laplace TS slightly outperforming Langevin TS.
3. **Convergence**: By t=5000, all agents approach a per-period regret of ~0.01, though the greedy and 0.01-greedy agents remain slightly above the TS agents.
### Interpretation
The graph demonstrates that **TS-based agents (Langevin and Laplace)** achieve lower per-period regret compared to greedy strategies over time. The **Laplace TS** agent appears to be the most efficient, as its line is consistently below the Langevin TS line. The **greedy** and **0.01-greedy** agents, while improving, lag behind the TS agents in long-term performance. This suggests that TS algorithms (likely Thompson Sampling variants) are more effective at balancing exploration and exploitation in dynamic environments. The 0.01-greedy agent’s slower improvement may indicate a trade-off between exploration and exploitation, possibly due to a reduced exploration parameter (e.g., ε = 0.01). The convergence of all lines to ~0.01 implies that all agents eventually stabilize, but the TS agents achieve this with lower regret.