# Technical Document Extraction: DeepSeek Architecture Overview
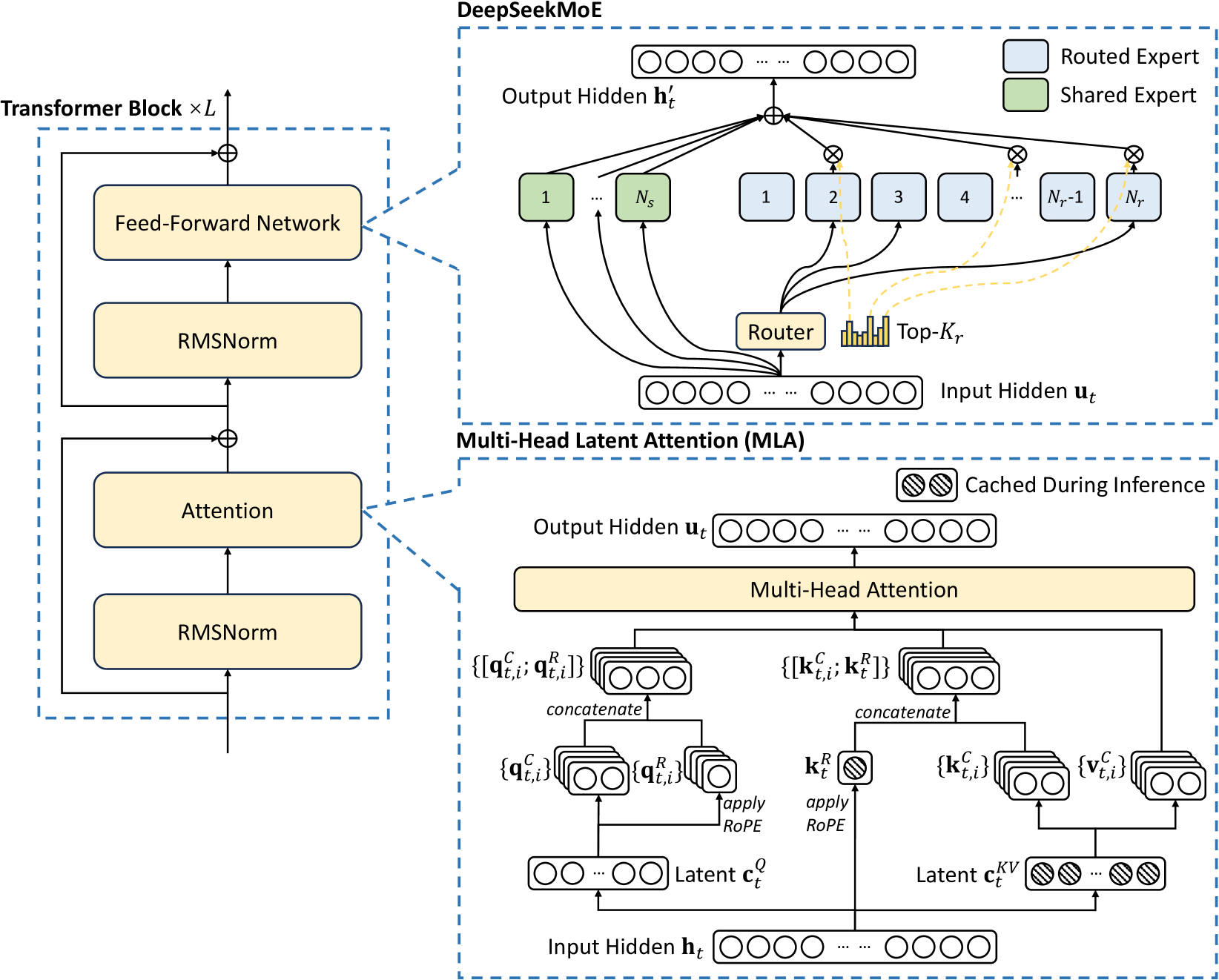
This document provides a comprehensive technical breakdown of the provided architectural diagram, which illustrates the components of a Transformer Block, specifically detailing the **DeepSeekMoE** and **Multi-Head Latent Attention (MLA)** mechanisms.
---
## 1. High-Level Structure: Transformer Block $\times L$
The left side of the image depicts the standard macro-architecture of a Transformer layer, which is repeated $L$ times.
### Components and Flow:
* **Input Path:** Data enters from the bottom.
* **Sub-layer 1 (Attention):**
* **RMSNorm:** The input first passes through Root Mean Square Normalization.
* **Attention:** The normalized signal enters the Attention block (detailed in the MLA section).
* **Residual Connection:** The original input is added to the output of the Attention block via an element-wise addition operator ($\oplus$).
* **Sub-layer 2 (Feed-Forward):**
* **RMSNorm:** The output of the first residual addition passes through a second normalization layer.
* **Feed-Forward Network:** The signal enters the FFN block (detailed in the DeepSeekMoE section).
* **Residual Connection:** The input to this sub-layer is added to the FFN output via an element-wise addition operator ($\oplus$).
* **Output:** The final processed signal exits at the top.
---
## 2. Component Detail: DeepSeekMoE
This section expands on the "Feed-Forward Network" block. It describes a Mixture-of-Experts (MoE) architecture.
### Legend [Top Right]:
* **Light Blue Box:** Routed Expert
* **Light Green Box:** Shared Expert
### Data Flow and Components:
1. **Input Hidden $\mathbf{u}_t$:** Represented as a vector of neurons.
2. **Routing Mechanism:**
* The input is sent to a **Router**.
* The Router generates a distribution, and a **Top-$K_r$** selection is made (visualized by a bar chart).
* Dashed yellow lines indicate the selection of specific "Routed Experts."
3. **Expert Processing:**
* **Shared Experts (Green):** Labeled $1$ through $N_s$. The input $\mathbf{u}_t$ is sent to all shared experts.
* **Routed Experts (Blue):** Labeled $1, 2, 3, 4, \dots, N_r-1, N_r$. Only the experts selected by the Top-$K_r$ gating receive the input.
4. **Aggregation:**
* Outputs from all active experts (Shared and Routed) are multiplied by their respective gating weights ($\otimes$).
* The weighted outputs are summed ($\oplus$).
5. **Output Hidden $\mathbf{h}'_t$:** The final aggregated vector.
---
## 3. Component Detail: Multi-Head Latent Attention (MLA)
This section expands on the "Attention" block, focusing on low-rank latent projections to reduce KV cache overhead.
### Legend [Top Right of MLA Box]:
* **Diagonal Striped Pattern:** Cached During Inference
### Data Flow and Components:
1. **Input Hidden $\mathbf{h}_t$:** The base input vector.
2. **Latent Projections:**
* **Query Path:** $\mathbf{h}_t$ is projected into a **Latent $\mathbf{c}_t^Q$**.
* **Key-Value Path:** $\mathbf{h}_t$ is projected into a **Latent $\mathbf{c}_t^{KV}$**. Note that $\mathbf{c}_t^{KV}$ is marked as **Cached During Inference**.
3. **Feature Extraction:**
* **From $\mathbf{c}_t^Q$:** Produces $\{\mathbf{q}_{t,i}^C\}$ (content query) and $\{\mathbf{q}_{t,i}^R\}$ (positional query via *apply RoPE*). These are concatenated to form $\{[\mathbf{q}_{t,i}^C; \mathbf{q}_{t,i}^R]\}$.
* **From $\mathbf{c}_t^{KV}$:** Produces $\{\mathbf{k}_{t,i}^C\}$ (content key) and $\{\mathbf{v}_{t,i}^C\}$ (content value).
* **Positional Key:** A separate path from $\mathbf{h}_t$ applies RoPE to generate $\mathbf{k}_t^R$ (marked as **Cached During Inference**).
* **Concatenation:** $\{\mathbf{k}_{t,i}^C\}$ and $\mathbf{k}_t^R$ are concatenated to form $\{[\mathbf{k}_{t,i}^C; \mathbf{k}_t^R]\}$.
4. **Attention Mechanism:**
* The processed Query, Key, and Value sets are fed into the **Multi-Head Attention** block.
5. **Output Hidden $\mathbf{u}_t$:** The final output vector of the attention mechanism.
---
## 4. Textual Transcriptions
### Labels and Variables:
* **Transformer Block $\times L$**
* **RMSNorm**
* **Attention**
* **Feed-Forward Network**
* **DeepSeekMoE**
* **Output Hidden $\mathbf{h}'_t$**
* **Shared Expert ($N_s$)**
* **Routed Expert ($N_r$)**
* **Router**
* **Top-$K_r$**
* **Input Hidden $\mathbf{u}_t$**
* **Multi-Head Latent Attention (MLA)**
* **Cached During Inference**
* **Multi-Head Attention**
* **Latent $\mathbf{c}_t^Q$**
* **Latent $\mathbf{c}_t^{KV}$**
* **apply RoPE**
* **concatenate**
* **Input Hidden $\mathbf{h}_t$**
### Mathematical Notations:
* $\{\mathbf{q}_{t,i}^C\}$ : Content Query
* $\{\mathbf{q}_{t,i}^R\}$ : RoPE Query
* $\{[\mathbf{q}_{t,i}^C; \mathbf{q}_{t,i}^R]\}$ : Concatenated Query
* $\mathbf{k}_t^R$ : RoPE Key
* $\{\mathbf{k}_{t,i}^C\}$ : Content Key
* $\{[\mathbf{k}_{t,i}^C; \mathbf{k}_t^R]\}$ : Concatenated Key
* $\{\mathbf{v}_{t,i}^C\}$ : Content Value