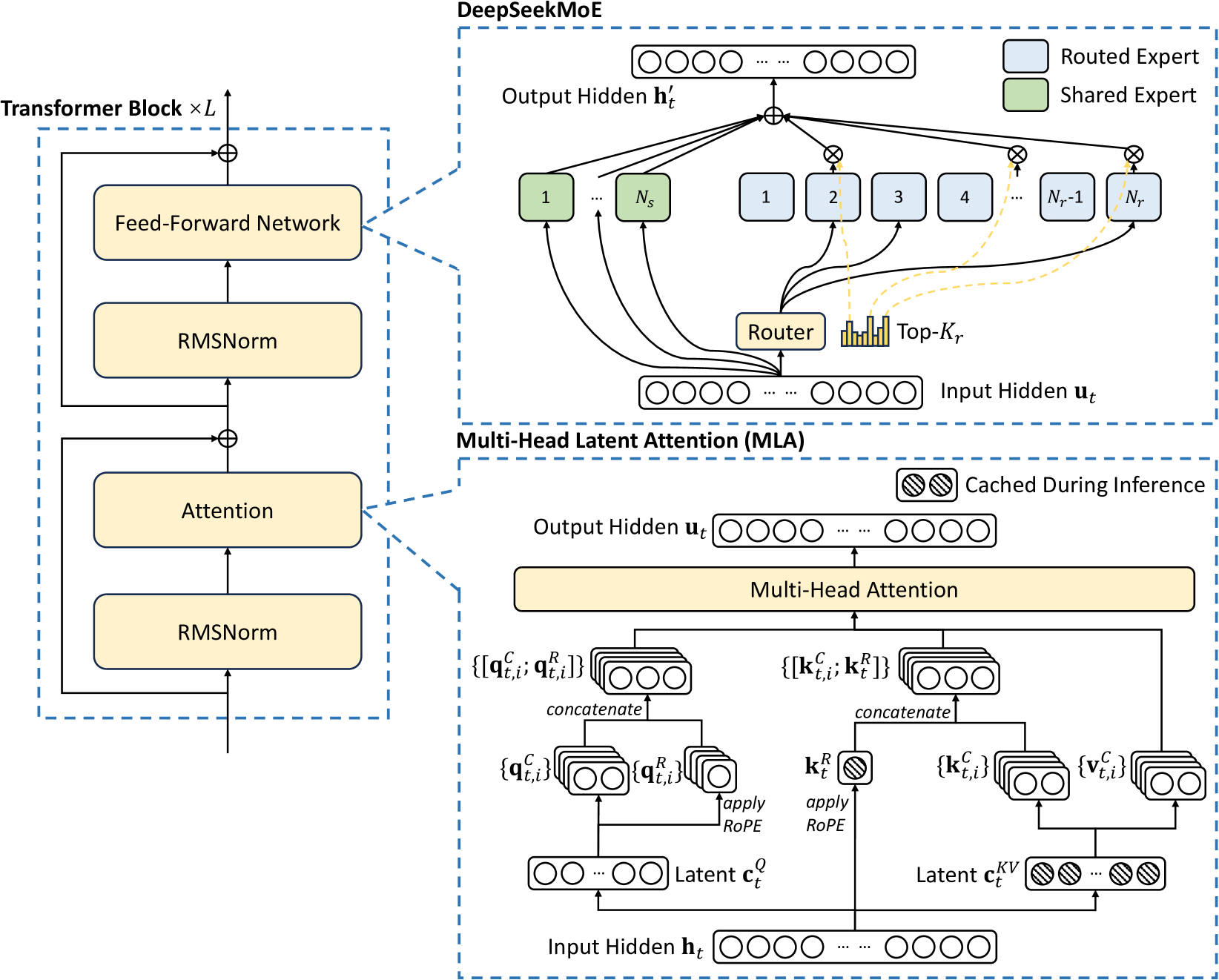
# Technical Diagram Analysis: Transformer Block and DeepSeekMoE Architecture
## Transformer Block (Left Section)
### Components and Flow:
1. **Input**: Unlabeled input vector (implied by arrow direction).
2. **Feed-Forward Network**:
- Rectangular block labeled "Feed-Forward Network".
- Receives input from previous layer.
3. **RMSNorm (1st Instance)**:
- Rectangular block labeled "RMSNorm".
- Receives output from Feed-Forward Network.
4. **Attention Mechanism**:
- Rectangular block labeled "Attention".
- Receives output from 1st RMSNorm.
5. **RMSNorm (2nd Instance)**:
- Rectangular block labeled "RMSNorm".
- Receives output from Attention mechanism.
6. **Output**: Unlabeled output vector (arrow points upward).
### Diagram Structure:
- Components arranged vertically in a stacked configuration.
- Arrows indicate sequential data flow between layers.
- No explicit input/output dimensions or activation functions specified.
---
## DeepSeekMoE Architecture (Right Section)
### Key Components:
1. **Input Hidden `h_t`**:
- Unlabeled input vector (top-left of diagram).
- Connected to Router via bidirectional arrows.
2. **Router**:
- Central component labeled "Router".
- Receives `h_t` and outputs routing probabilities.
- Contains histogram labeled "Top-K_r" (expert selection threshold).
3. **Experts**:
- **Routed Experts (N_r total)**:
- Labeled 1 to N_r (e.g., 1, 2, 3, ..., N_r-1, N_r).
- Represented by blue rectangles (per legend).
- Connected to `h_t` via dashed lines.
- **Shared Expert (N_s total)**:
- Labeled N_s (green rectangle, per legend).
- Connected to `h_t` via dashed lines.
4. **Output Hidden `h'_t`**:
- Unlabeled output vector (top-center).
- Result of expert processing.
5. **Multi-Head Latent Attention (MILA)**:
- Sub-diagram labeled "Multi-Head Latent Attention (MILA)".
- **Input Hidden `u_t`**:
- Unlabeled input vector (bottom-left of MILA sub-diagram).
- **Components**:
- **Queries (Q)**:
- Concatenated vectors labeled `{q^C_t,i}` and `{q^R_t,i}`.
- Processed through RoPE (Rotary Positional Encoding).
- **Keys (K)**:
- Concatenated vectors labeled `{k^C_t,i}` and `{k^R_t}`.
- Processed through RoPE.
- **Values (V)**:
- Vectors labeled `{v^C_t,i}`.
- **Latent Vectors**:
- `c^Q_t` (unlabeled latent query vector).
- `c^KV_t` (unlabeled latent key-value vector).
- **Output Hidden `u_t`**:
- Unlabeled output vector (bottom-right of MILA sub-diagram).
### Diagram Structure:
- **Top Section**: Router and expert routing logic.
- **Bottom Section**: MILA sub-diagram with attention mechanisms.
- **Caching**: Striped boxes indicate cached components during inference.
---
## Legend and Color Coding
- **Blue Rectangles**: Routed Experts (N_r).
- **Green Rectangles**: Shared Expert (N_s).
- **Dashed Lines**: Connections between Router and experts.
- **Solid Lines**: Data flow within Transformer Block and MILA.
---
## Key Trends and Connections
1. **Transformer Block**:
- Standard architecture with two RMSNorm layers sandwiching an Attention mechanism.
- No residual connections explicitly shown.
2. **DeepSeekMoE**:
- **Routing**: Dynamic expert selection via Top-K_r threshold.
- **Expert Diversity**: Combination of routed (specialized) and shared (general) experts.
- **Efficiency**: Caching mechanism for latent vectors during inference.
3. **MILA**:
- Hybrid attention mechanism combining cached and real-time processing.
- Latent vectors (`c^Q_t`, `c^KV_t`) reduce computational overhead.
---
## Missing Information
- No explicit dimensions for input/output vectors.
- No activation functions specified for Feed-Forward Network.
- No numerical values for N_r, N_s, or K_r.
- No details about RoPE implementation specifics.