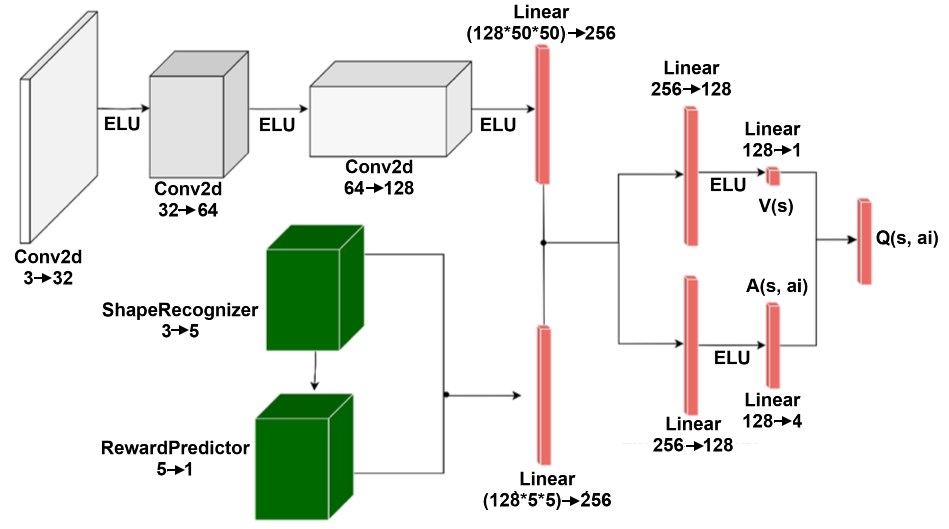
## Diagram: Neural Network Architecture (Dueling DQN with Auxiliary Reward Prediction)
### Overview
The image displays a deep reinforcement learning neural network architecture. The diagram is composed of two primary processing streams: a top visual processing pipeline (grey blocks) and a bottom auxiliary task pipeline (green blocks). These streams converge into a Dueling DQN (Deep Q-Network) structure, which splits into Value ($V(s)$) and Advantage ($A(s, ai)$) streams before merging into a final output ($Q(s, ai)$).
### Components/Axes
* **Grey Cubes:** Convolutional layers (`Conv2d`).
* **Green Cubes:** Auxiliary task modules (`ShapeRecognizer`, `RewardPredictor`).
* **Red Bars:** Fully connected (`Linear`) layers.
* **Labels:** `ELU` (Exponential Linear Unit) activation functions.
* **Flow:** The diagram flows from left to right.
### Detailed Analysis
#### 1. Top Branch (Visual Processing Pipeline)
Located in the upper-left to center-left region, this branch processes visual input through a series of convolutional layers:
* **Input:** `Conv2d 3->32` (Grey cube).
* **Activation:** `ELU` (arrow).
* **Layer 2:** `Conv2d 32->64` (Grey cube).
* **Activation:** `ELU` (arrow).
* **Layer 3:** `Conv2d 64->128` (Grey cube).
* **Activation:** `ELU` (arrow).
* **Flattening/Linear:** `Linear (128*50*50)->256` (Tall red bar).
#### 2. Bottom Branch (Auxiliary Task Pipeline)
Located in the lower-left region, this branch processes auxiliary information:
* **Module 1:** `ShapeRecognizer 3->5` (Green cube).
* **Module 2:** `RewardPredictor 5->1` (Green cube).
* **Linear:** `Linear (128*5*5)->256` (Tall red bar, bottom-center).
#### 3. Dueling DQN Structure (Right Side)
The output of the top branch (the first red bar) splits at a junction point (indicated by a dot).
* **Top Path (Value Stream):**
* `Linear 256->128` (Red bar).
* `ELU` (Activation).
* `Linear 128->1` (Small red bar).
* **Output:** `V(s)` (Value of state).
* **Bottom Path (Advantage Stream):**
* `Linear 256->128` (Red bar).
* *Note:* The output from the bottom branch (`Linear (128*5*5)->256`) feeds into this specific `Linear 256->128` layer.
* `ELU` (Activation).
* `Linear 128->4` (Small red bar).
* **Output:** `A(s, ai)` (Advantage of action $i$ in state $s$).
#### 4. Final Output
* The `V(s)` and `A(s, ai)` streams merge into a final node: `Q(s, ai)` (Red bar, far right).
### Key Observations
* **Architecture Type:** This is a Dueling DQN architecture, which is designed to decouple the estimation of the state value ($V$) and the advantage of each action ($A$).
* **Auxiliary Task:** The inclusion of the `ShapeRecognizer` and `RewardPredictor` (green blocks) suggests this model uses auxiliary tasks to improve feature representation learning, likely to speed up convergence or improve sample efficiency.
* **Data Flow:** The auxiliary task (RewardPredictor) is injected into the Advantage stream, suggesting the auxiliary information is specifically used to help the model distinguish between the relative benefits of different actions.
### Interpretation
This diagram represents a sophisticated reinforcement learning agent. By separating the network into a visual encoder (top) and an auxiliary task (bottom), the model learns a more robust representation of the environment.
The "Dueling" aspect is critical: by splitting the final layers into $V(s)$ and $A(s, ai)$, the network can learn which states are valuable without needing to learn the effect of each action for every state. This is particularly useful in environments where many actions have the same effect, or where the value of the state is independent of the actions taken. The auxiliary `RewardPredictor` likely acts as a regularizer or a feature-enhancer, forcing the network to learn features that are predictive of rewards, which helps the agent focus on relevant visual information.