## Neural Network Architecture Diagram: Reinforcement Learning Agent
### Overview
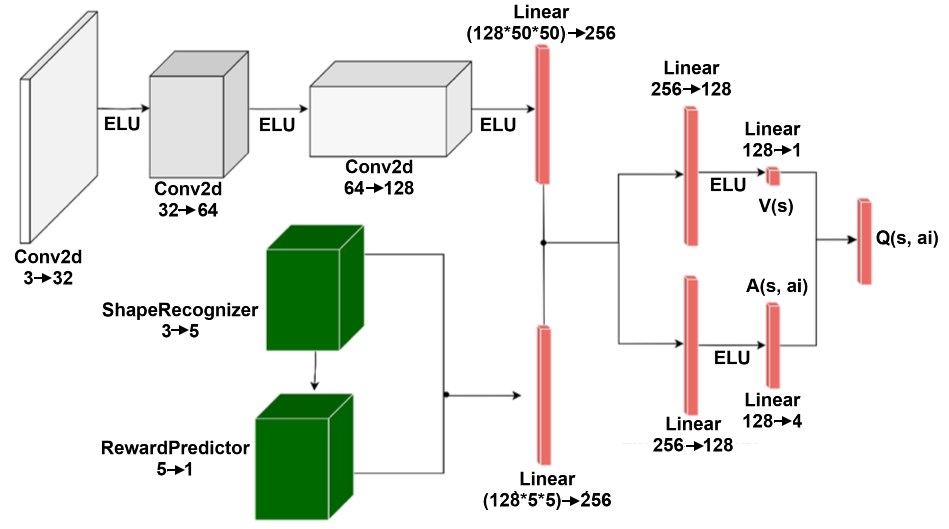
The diagram illustrates a neural network architecture for a reinforcement learning agent. It combines convolutional layers for feature extraction with specialized branches for shape recognition and reward prediction, culminating in a Q-value output for action selection.
### Components/Axes
- **Input Layer**: Conv2d (3→32)
- **Activation Functions**: ELU (applied after each Conv2d layer)
- **Convolutional Layers**:
- Conv2d (32→64)
- Conv2d (64→128)
- **Linear Layers**:
- Linear (128×50×50→256)
- Linear (256→128)
- Linear (128→4)
- Linear (128→1)
- **Specialized Branches**:
- ShapeRecognizer (3→5)
- RewardPredictor (5→1)
- **Output**: Q(s, a_i) (final Q-value)
### Detailed Analysis
1. **Main Path**:
- Input (Conv2d 3→32) → ELU → Conv2d (32→64) → ELU → Conv2d (64→128) → ELU → Linear (128×50×50→256)
- Branches:
- **Shape Recognition**: Linear (256→128) → ELU → Linear (128→5) → ShapeRecognizer (3→5)
- **Reward Prediction**: Linear (256→128) → ELU → Linear (128→1) → RewardPredictor (5→1)
- Final Output: Linear (128→1) → Q(s, a_i)
2. **Color Coding**:
- Gray: Main convolutional/linear path
- Green: Specialized branches (ShapeRecognizer, RewardPredictor)
3. **Dimensional Flow**:
- Spatial dimensions reduce through convolutions (32→64→128)
- Channel dimensions expand through linear layers (256→128→4→1)
### Key Observations
- **Modular Design**: Separate branches handle distinct tasks (shape recognition vs. reward prediction)
- **Dimensional Reduction**: Input dimensions shrink from 50×50 to 1×1 through progressive convolutions
- **Non-Linearity**: ELU activation used consistently after convolutional layers
- **Action-Value Integration**: Final Q-value combines outputs from both branches
### Interpretation
This architecture demonstrates a hierarchical approach to reinforcement learning:
1. **Feature Extraction**: Early convolutional layers capture spatial features
2. **Task Specialization**: Dedicated branches process different aspects of the input
3. **Value Integration**: Final Q-value combines shape information and reward predictions
The design suggests an agent that:
- Processes visual input (Conv2d layers)
- Recognizes object shapes (ShapeRecognizer)
- Predicts rewards (RewardPredictor)
- Evaluates actions (Q(s, a_i))
The use of ELU activations and progressive dimensional reduction indicates optimization for stability and computational efficiency. The specialized branches allow the model to handle complex decision-making by decomposing the problem into shape analysis and reward evaluation.