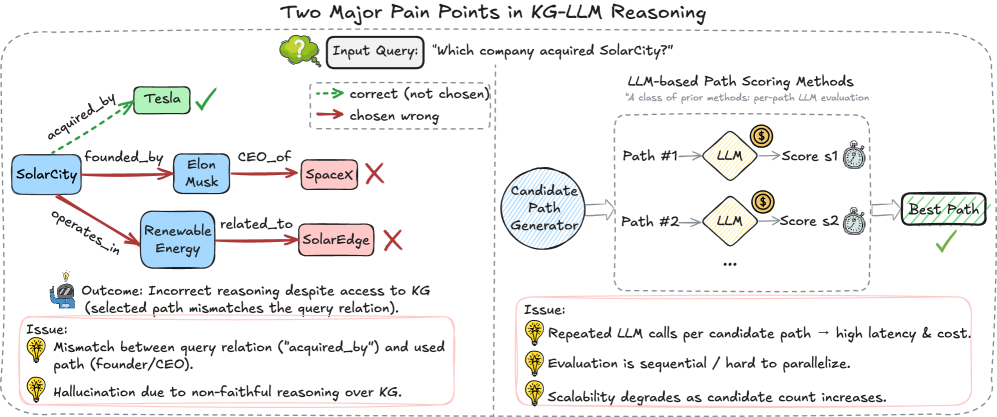
## Diagram: Two Major Pain Points in KG-LLM Reasoning
### Overview
The image is a diagram illustrating two major pain points in Knowledge Graph (KG) - Large Language Model (LLM) reasoning. It shows an example of incorrect reasoning by an LLM when answering a question about a knowledge graph, and it outlines the process of LLM-based path scoring, highlighting issues related to latency, cost, and scalability.
### Components/Axes
* **Title:** Two Major Pain Points in KG-LLM Reasoning
* **Input Query:** "Which company acquired SolarCity?"
* **Legend:**
* Green dashed arrow: correct (not chosen)
* Red solid arrow: chosen wrong
* **Knowledge Graph (Left Side):**
* Nodes: SolarCity, Tesla, Elon Musk, SpaceX, Renewable Energy, SolarEdge
* Edges: acquired\_by, founded\_by, CEO\_of, operates\_in, related\_to
* **LLM-based Path Scoring Methods (Right Side):**
* Candidate Path Generator
* LLM (appears twice)
* Score s1, Score s2
* Best Path
* **Outcome:** Incorrect reasoning despite access to KG (selected path mismatches the query relation).
* **Issues (Left Side):**
* Mismatch between query relation ("acquired\_by") and used path (founder/CEO).
* Hallucination due to non-faithful reasoning over KG.
* **Issues (Right Side):**
* Repeated LLM calls per candidate path -> high latency & cost.
* Evaluation is sequential / hard to parallelize.
* Scalability degrades as candidate count increases.
### Detailed Analysis
**Knowledge Graph (Left Side):**
* **SolarCity** is connected to **Tesla** via a green dashed arrow labeled "acquired\_by" with a green checkmark, indicating the correct answer.
* **SolarCity** is connected to **Elon Musk** via a red solid arrow labeled "founded\_by".
* **Elon Musk** is connected to **SpaceX** via a red solid arrow labeled "CEO\_of" with a red X, indicating an incorrect path.
* **SolarCity** is connected to **Renewable Energy** via a red solid arrow labeled "operates\_in".
* **Renewable Energy** is connected to **SolarEdge** via a red solid arrow labeled "related\_to" with a red X, indicating an incorrect path.
**LLM-based Path Scoring Methods (Right Side):**
* The **Candidate Path Generator** outputs two paths: Path #1 and Path #2.
* Each path is processed by an **LLM**.
* The LLM assigns a score to each path: Score s1 for Path #1 and Score s2 for Path #2.
* The path with the highest score is selected as the **Best Path**, indicated by a green checkmark.
**Issues (Left Side):**
* The diagram highlights that the LLM's reasoning is incorrect despite having access to the knowledge graph.
* The selected path (founder/CEO) mismatches the query relation (acquired\_by).
* The LLM exhibits hallucination due to non-faithful reasoning over the knowledge graph.
**Issues (Right Side):**
* Repeated LLM calls per candidate path lead to high latency and cost.
* Evaluation is sequential, making it hard to parallelize.
* Scalability degrades as the candidate count increases.
### Key Observations
* The diagram illustrates how an LLM can fail to correctly answer a question about a knowledge graph, even when the correct information is present.
* The LLM's incorrect reasoning is attributed to a mismatch between the query relation and the selected path, as well as hallucination.
* The LLM-based path scoring method suffers from issues related to latency, cost, and scalability.
### Interpretation
The diagram highlights the challenges of using LLMs for reasoning over knowledge graphs. While LLMs have the potential to answer complex questions based on structured knowledge, they can also make mistakes due to incorrect reasoning, hallucination, and scalability issues. The diagram suggests that further research is needed to improve the accuracy and efficiency of LLM-based knowledge graph reasoning methods. The issues on the right side of the diagram suggest that the process is computationally expensive and difficult to scale, which could limit its applicability in real-world scenarios.