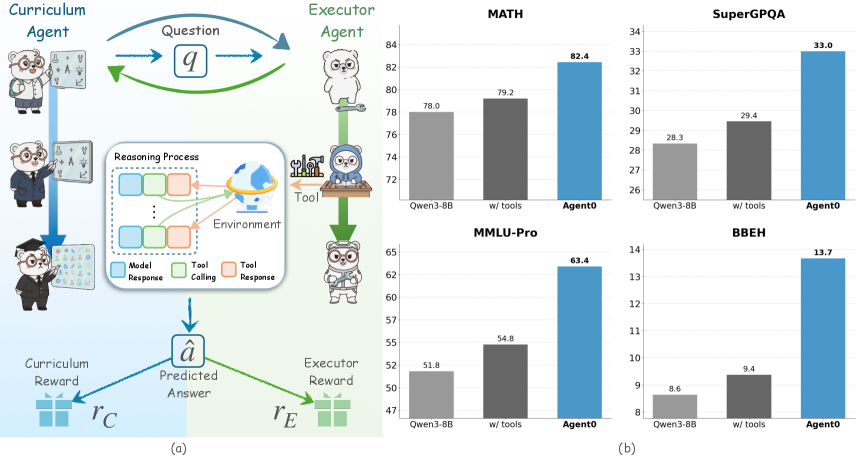
## Workflow Diagram and Bar Charts: Agent Performance
### Overview
The image presents a workflow diagram illustrating the interaction between a Curriculum Agent and an Executor Agent, alongside bar charts comparing the performance of different models (Qwen3-8B, Qwen3-8B with tools, and Agent0) on various benchmarks (MATH, SuperGPQA, MMLU-Pro, and BBEH).
### Components/Axes
**Part (a): Workflow Diagram**
* **Title:** Curriculum Agent vs. Executor Agent
* **Agents:**
* Curriculum Agent: Represented by a bear character in three stages: student, intern, and graduate.
* Executor Agent: Represented by a bear character in three stages: standing, using tools, and wearing a hard hat.
* **Flow:**
* The Curriculum Agent poses a "Question" (q) to the Executor Agent.
* The Executor Agent engages in a "Reasoning Process" within an "Environment," potentially using "Tool" (tool calling and tool response).
* The Executor Agent produces a "Predicted Answer" (â).
* Both agents receive rewards: Curriculum Reward (rC) and Executor Reward (rE).
* **Reasoning Process Legend:**
* Model Response (blue)
* Tool Calling (green)
* Tool Response (orange)
**Part (b): Bar Charts**
* **General Layout:** Four bar charts arranged in a 2x2 grid. Each chart compares the performance of three models: Qwen3-8B, Qwen3-8B with tools, and Agent0.
* **X-axis:** Model type (Qwen3-8B, w/ tools, Agent0)
* **Y-axis:** Performance score (varies by benchmark)
* **Bar Colors:**
* Qwen3-8B: Light gray
* w/ tools: Dark gray
* Agent0: Blue
### Detailed Analysis
**MATH Benchmark**
* **Y-axis:** Scale from 72 to 84
* **Qwen3-8B:** 78.0
* **w/ tools:** 79.2
* **Agent0:** 82.4
* **Trend:** Performance increases from Qwen3-8B to w/ tools to Agent0.
**SuperGPQA Benchmark**
* **Y-axis:** Scale from 26 to 34
* **Qwen3-8B:** 28.3
* **w/ tools:** 29.4
* **Agent0:** 33.0
* **Trend:** Performance increases from Qwen3-8B to w/ tools to Agent0.
**MMLU-Pro Benchmark**
* **Y-axis:** Scale from 47 to 65
* **Qwen3-8B:** 51.8
* **w/ tools:** 54.8
* **Agent0:** 63.4
* **Trend:** Performance increases from Qwen3-8B to w/ tools to Agent0.
**BBEH Benchmark**
* **Y-axis:** Scale from 8 to 14
* **Qwen3-8B:** 8.6
* **w/ tools:** 9.4
* **Agent0:** 13.7
* **Trend:** Performance increases from Qwen3-8B to w/ tools to Agent0.
### Key Observations
* In all four benchmarks, Agent0 consistently outperforms Qwen3-8B and Qwen3-8B with tools.
* Using tools generally improves the performance of Qwen3-8B, but the improvement is not as significant as using Agent0.
* The workflow diagram illustrates a reinforcement learning setup where agents learn through interaction and feedback.
### Interpretation
The data suggests that Agent0 is a more effective model for the given benchmarks compared to Qwen3-8B, even when Qwen3-8B is augmented with external tools. The workflow diagram provides context for how these models might be trained and evaluated within a reinforcement learning framework. The consistent outperformance of Agent0 across different benchmarks indicates its robustness and potential for generalization. The use of tools improves Qwen3-8B's performance, suggesting that tool integration is a valuable strategy for enhancing model capabilities.