TECHNICAL ASSET FINGERPRINT
a6acc620098965c7e49989cc
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
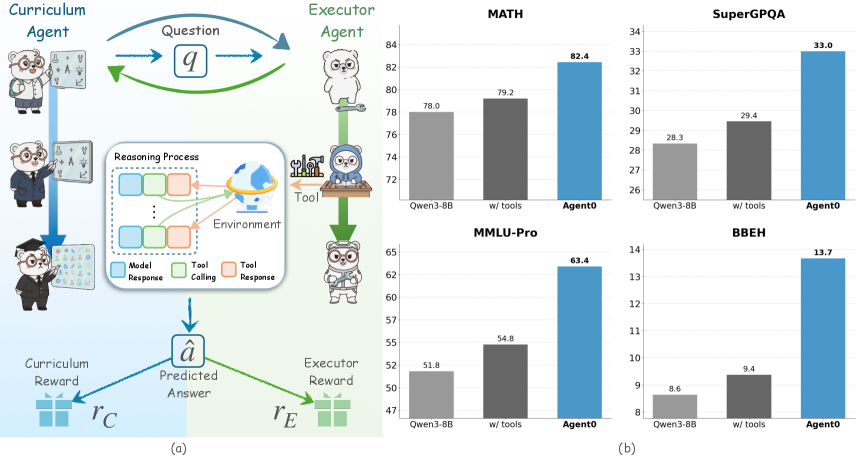
## Diagram and Bar Charts: Multi-Agent System Performance Comparison
### Overview
The image is a composite figure containing two main panels. Panel (a) on the left is a system architecture diagram illustrating a multi-agent framework involving a "Curriculum Agent" and an "Executor Agent." Panel (b) on the right consists of four bar charts comparing the performance of three models ("Qwen3-8B", "w/ tools", and "Agent0") across four different benchmarks: MATH, SuperGPQA, MMLU-Pro, and BBEH.
### Components/Axes
#### Panel (a): System Architecture Diagram
* **Top Section:**
* **Left Agent:** Labeled "Curriculum Agent". Depicted as a cartoon bear in a graduation cap and gown, holding a scroll.
* **Right Agent:** Labeled "Executor Agent". Depicted as a cartoon bear in a lab coat, holding a wrench.
* **Central Element:** A box labeled "Question" containing the symbol "q". Arrows flow from the Curriculum Agent to the Question box and from the Question box to the Executor Agent. A green arrow also flows back from the Executor Agent to the Curriculum Agent.
* **Middle Section:**
* **Left Flow:** A blue arrow descends from the Curriculum Agent to a second bear icon (in a suit), then to a third bear icon (in a graduation cap), pointing towards a box labeled "Predicted Answer" with the symbol "â".
* **Central Process Box:** Labeled "Reasoning Process". Contains a flowchart with three colored boxes: "Model Response" (blue), "Tool Calling" (green), and "Tool Response" (orange). Arrows connect these boxes in a cycle. An icon labeled "Environment" (depicting a globe with a satellite) is connected to this process.
* **Right Flow:** A green arrow descends from the Executor Agent to a bear icon at a desk with a computer, then to another bear icon holding a magnifying glass, pointing towards the "Predicted Answer" box.
* **Bottom Section:**
* **Central Output:** A box labeled "Predicted Answer" containing the symbol "â".
* **Reward Signals:** Two arrows originate from the "Predicted Answer" box.
* A blue arrow points left to a gift box icon labeled "Curriculum Reward" with the symbol "r_C".
* A green arrow points right to a gift box icon labeled "Executor Reward" with the symbol "r_E".
#### Panel (b): Performance Bar Charts
* **Common Elements:**
* **X-axis (All Charts):** Three categories: "Qwen3-8B" (light gray bar), "w/ tools" (dark gray bar), "Agent0" (blue bar).
* **Y-axis:** Numerical score for each benchmark. The scale varies per chart.
* **Chart 1 (Top-Left): MATH**
* **Title:** "MATH"
* **Y-axis Range:** Approximately 70 to 84.
* **Data Points:**
* Qwen3-8B: 78.0
* w/ tools: 79.2
* Agent0: 82.4
* **Chart 2 (Top-Right): SuperGPQA**
* **Title:** "SuperGPQA"
* **Y-axis Range:** Approximately 26 to 34.
* **Data Points:**
* Qwen3-8B: 28.3
* w/ tools: 29.4
* Agent0: 33.0
* **Chart 3 (Bottom-Left): MMLU-Pro**
* **Title:** "MMLU-Pro"
* **Y-axis Range:** Approximately 47 to 65.
* **Data Points:**
* Qwen3-8B: 51.8
* w/ tools: 54.8
* Agent0: 63.4
* **Chart 4 (Bottom-Right): BBEH**
* **Title:** "BBEH"
* **Y-axis Range:** Approximately 8 to 14.
* **Data Points:**
* Qwen3-8B: 8.6
* w/ tools: 9.4
* Agent0: 13.7
### Detailed Analysis
* **Diagram Flow (Panel a):** The diagram illustrates a closed-loop, multi-agent system. The Curriculum Agent generates or selects a question (`q`). This question is processed by the Executor Agent, which engages in a "Reasoning Process" involving model responses and tool interactions with an "Environment." The final output is a "Predicted Answer" (`â`). This answer is evaluated, generating two distinct reward signals: a "Curriculum Reward" (`r_C`) fed back to the Curriculum Agent, and an "Executor Reward" (`r_E`) fed back to the Executor Agent. This suggests a reinforcement learning setup where both agents are optimized based on the outcome.
* **Performance Trends (Panel b):** Across all four benchmarks, a consistent performance hierarchy is observed:
1. **Agent0 (Blue Bar):** Achieves the highest score in every chart.
2. **w/ tools (Dark Gray Bar):** Performs better than the base model but worse than Agent0.
3. **Qwen3-8B (Light Gray Bar):** Has the lowest score in every comparison.
* **Magnitude of Improvement:** The performance gap between "Agent0" and the other models varies by task.
* The smallest absolute gain is on the **MATH** benchmark (+4.4 points over Qwen3-8B).
* The largest relative gains appear on the **BBEH** benchmark, where Agent0's score (13.7) is approximately 59% higher than Qwen3-8B's (8.6).
### Key Observations
1. **Consistent Superiority:** Agent0 demonstrates a clear and consistent performance advantage over both the base model (Qwen3-8B) and the model augmented with tools ("w/ tools") across diverse reasoning and knowledge benchmarks (MATH, SuperGPQA, MMLU-Pro, BBEH).
2. **Tool Use Benefit:** The "w/ tools" configuration consistently outperforms the base "Qwen3-8B" model, indicating that providing tool access improves performance on these tasks.
3. **Architectural Synergy:** The diagram in panel (a) provides a potential explanation for the results in panel (b). It depicts a sophisticated system where specialized agents (Curriculum and Executor) collaborate, utilize tools, and are trained via reward signals. This complex architecture likely underpins the "Agent0" model, explaining its superior performance compared to simpler baselines.
4. **Task Diversity:** The benchmarks cover a range of domains: quantitative reasoning (MATH), graduate-level question answering (SuperGPQA), broad multidisciplinary knowledge (MMLU-Pro), and likely a specialized reasoning task (BBEH). Agent0's lead across all of them suggests robust generalization.
### Interpretation
The data presents a compelling case for the efficacy of the multi-agent, tool-augmented framework illustrated in panel (a). The "Agent0" model, which presumably implements this framework, doesn't just marginally improve upon baselines; it establishes a new performance ceiling on each benchmark.
The relationship between the two panels is causal and explanatory. Panel (a) is the *method*—a system designed for collaborative reasoning and learning through environmental interaction and reward. Panel (b) is the *result*—empirical evidence that this method produces a more capable model. The consistent ranking (Agent0 > w/ tools > Base) across varied tasks suggests the improvements are not coincidental or task-specific but stem from fundamental architectural advantages.
The "Reasoning Process" box is particularly insightful. It shows that the system's strength likely comes from dynamically interleaving internal model reasoning ("Model Response") with external action ("Tool Calling") and observation ("Tool Response"). This closed-loop interaction with an "Environment" allows for verification, information retrieval, and complex problem-solving steps that a static model cannot perform. The separate reward signals for the Curriculum and Executor agents further suggest a sophisticated training regime where each component is optimized for its specific role in the overall problem-solving pipeline.
In essence, the figure argues that moving beyond a single, monolithic model to a structured, multi-agent system with tool use and specialized training leads to significant and consistent gains in AI capability across challenging domains.
DECODING INTELLIGENCE...