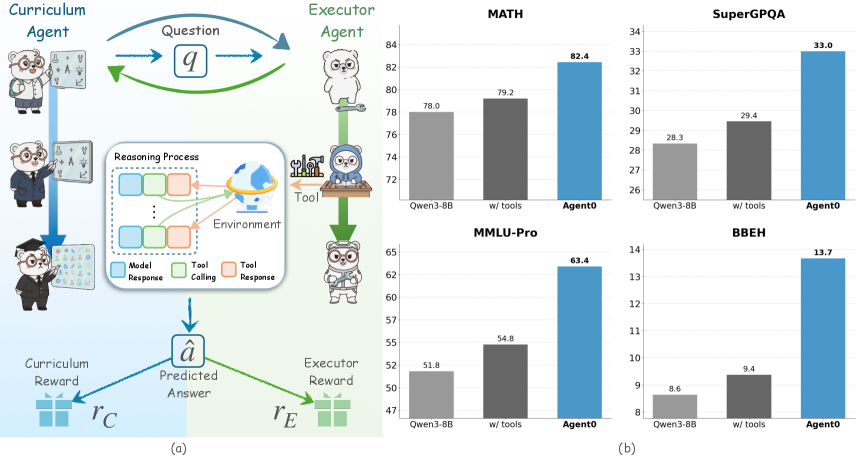
## Diagram: Curriculum-Executor Agent System Architecture
### Overview
The diagram illustrates a two-agent system with feedback loops for curriculum learning. The **Curriculum Agent** (left) and **Executor Agent** (right) interact through a question (`q`) and reasoning process involving model responses, tool calls, and tool responses. Rewards (`r_C`, `r_E`) are generated based on predicted answers (`â`).
### Components/Axes
- **Left Side (Curriculum Agent)**:
- Labels: "Curriculum Agent" (three anthropomorphic figures: teacher, student, researcher).
- Arrows: Blue arrow labeled `q` (question) pointing to Executor Agent.
- Reward: Blue arrow labeled `r_C` (Curriculum Reward) pointing to `â` (Predicted Answer).
- **Center (Reasoning Process)**:
- Boxes:
- Blue: "Model Response"
- Green: "Tool Calling"
- Orange: "Tool Response"
- Globe icon labeled "Environment."
- **Right Side (Executor Agent)**:
- Labels: "Executor Agent" (three anthropomorphic figures: tool user, evaluator, analyst).
- Arrows: Green arrow labeled `â` (Predicted Answer) pointing to Tool.
- Reward: Green arrow labeled `r_E` (Executor Reward) pointing to `â`.
- **Legend**:
- Blue: Model Response
- Green: Tool Calling
- Orange: Tool Response
### Detailed Analysis
- **Flow**:
1. Curriculum Agent generates a question (`q`).
2. Executor Agent uses tools (e.g., calculator, database) to process `q`.
3. Feedback loops:
- Curriculum Reward (`r_C`) adjusts `â` based on correctness.
- Executor Reward (`r_E`) evaluates tool effectiveness.
### Key Observations
- The system emphasizes iterative learning via rewards and tool integration.
- Tool responses (`Tool Response`) are critical for refining predictions (`â`).
---
## Bar Charts: Task Performance Comparison
### Overview
Four bar charts compare performance metrics (percentage) across tasks: **MATH**, **SuperGPQA**, **MMLU-Pro**, and **BBEH**. Three methods are evaluated: **Owen3-BB**, **w/ tools**, and **Agent0**.
### Components/Axes
- **X-Axis**: Methods (Owen3-BB, w/ tools, Agent0).
- **Y-Axis**: Performance (%) with approximate values:
- **MATH**: 78.0% (Owen3-BB), 79.2% (w/ tools), 82.4% (Agent0).
- **SuperGPQA**: 28.3% (Owen3-BB), 29.4% (w/ tools), 33.0% (Agent0).
- **MMLU-Pro**: 51.8% (Owen3-BB), 54.8% (w/ tools), 63.4% (Agent0).
- **BBEH**: 8.6% (Owen3-BB), 9.4% (w/ tools), 13.7% (Agent0).
- **Legend**:
- Blue: Agent0
- Dark Gray: w/ tools
- Light Gray: Owen3-BB
### Detailed Analysis
- **Trends**:
- **Agent0** consistently outperforms other methods across all tasks.
- **w/ tools** improves performance over Owen3-BB but lags behind Agent0.
- **BBEH** shows the lowest scores, indicating poor task alignment.
### Key Observations
- Agent0 achieves **82.4% in MATH** (highest) and **13.7% in BBEH** (lowest among top performers).
- Owen3-BB underperforms in all tasks compared to w/ tools and Agent0.
---
## Interpretation
### System Architecture (Diagram)
The diagram highlights a symbiotic relationship between curriculum and execution agents. The Curriculum Agent focuses on knowledge structuring (`r_C`), while the Executor Agent leverages tools for real-world problem-solving (`r_E`). The feedback loops suggest adaptive learning, where rewards refine both prediction accuracy (`â`) and tool utility.
### Task Performance (Bar Charts)
- **Agent0’s Dominance**: Outperforms baseline methods (Owen3-BB, w/ tools) in all tasks, suggesting superior integration of curriculum learning and tool usage.
- **Tool Impact**: Adding tools (`w/ tools`) improves performance by ~1-5% over Owen3-BB, but Agent0’s holistic approach yields larger gains (e.g., +3.2% in MATH).
- **BBEH Anomaly**: Despite Agent0’s improvement, BBEH scores remain low (≤13.7%), indicating potential task-specific limitations or misalignment with Agent0’s design.
### Implications
- **Agent0’s Strengths**: Effective in structured tasks (MATH, MMLU-Pro) but struggles with BBEH, hinting at domain-specific challenges.
- **Tool Dependency**: While tools enhance performance, Agent0’s end-to-end learning likely reduces reliance on external tools compared to `w/ tools`.
- **Curriculum Reward (`r_C`)**: Critical for aligning predictions (`â`) with educational goals, as seen in Agent0’s consistent gains.
This analysis underscores the value of integrated curriculum-execution systems for adaptive reasoning, with Agent0 representing a significant advancement over incremental tool-based approaches.