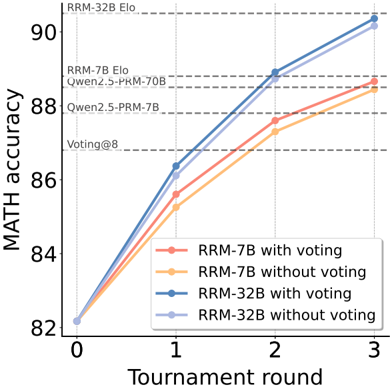
## Line Chart: MATH Accuracy vs. Tournament Round
### Overview
The image is a line chart comparing the MATH accuracy of different models (RRM-7B and RRM-32B) with and without voting, across tournament rounds (0 to 3). The chart also includes horizontal dashed lines indicating the performance of other models like RRM-32B Elo, RRM-7B Elo, Qwen2.5-PRM-70B, Qwen2.5-PRM-7B, and Voting@8.
### Components/Axes
* **X-axis:** Tournament round, with values 0, 1, 2, and 3.
* **Y-axis:** MATH accuracy, ranging from 82 to 90.
* **Legend (bottom-right):**
* Red: RRM-7B with voting
* Orange: RRM-7B without voting
* Blue: RRM-32B with voting
* Light Blue: RRM-32B without voting
* **Horizontal dashed lines (top-left):**
* RRM-32B Elo (at approximately 90.5)
* RRM-7B Elo, Qwen2.5-PRM-70B (at approximately 88.8)
* Qwen2.5-PRM-7B (at approximately 87.8)
* Voting@8 (at approximately 87)
### Detailed Analysis
* **RRM-7B with voting (Red):**
* Trend: Slopes upward.
* Data points: (0, 82), (1, 85.5), (2, 87.5), (3, 88.5)
* **RRM-7B without voting (Orange):**
* Trend: Slopes upward.
* Data points: (0, 82), (1, 85), (2, 87), (3, 88.2)
* **RRM-32B with voting (Blue):**
* Trend: Slopes upward.
* Data points: (0, 82.2), (1, 86.5), (2, 88.5), (3, 90)
* **RRM-32B without voting (Light Blue):**
* Trend: Slopes upward.
* Data points: (0, 82.2), (1, 86), (2, 88), (3, 89.8)
### Key Observations
* Both RRM-32B models (with and without voting) consistently outperform the RRM-7B models.
* For both model sizes (7B and 32B), using voting generally results in slightly higher MATH accuracy.
* The performance gap between the models appears to narrow as the tournament round increases, but RRM-32B maintains the lead.
* The RRM-32B with voting model approaches the performance level of "RRM-32B Elo" by round 3.
### Interpretation
The chart demonstrates the impact of model size and voting on MATH accuracy in a tournament setting. The RRM-32B models, being larger, achieve higher accuracy than the RRM-7B models. The use of voting enhances the performance of both models, although the effect seems more pronounced in earlier rounds. The convergence of the lines suggests that the benefit of additional tournament rounds diminishes as the models approach their performance ceiling. The horizontal lines provide a benchmark against other models, indicating the relative performance of the RRM models in comparison to established models like RRM-32B Elo, RRM-7B Elo, Qwen2.5-PRM-70B, Qwen2.5-PRM-7B, and Voting@8. The data suggests that increasing model size and incorporating voting are effective strategies for improving MATH accuracy.