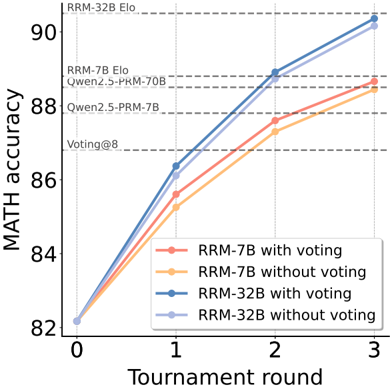
\n
## Line Chart: MATH Accuracy vs. Tournament Round
### Overview
This line chart depicts the relationship between MATH accuracy and tournament round for four different model configurations. The models are RRM-7B with and without voting, and RRM-32B with and without voting. The chart shows how accuracy changes as the tournament progresses from round 0 to round 3. Horizontal dashed lines indicate Elo ratings for different models.
### Components/Axes
* **X-axis:** Tournament round (0, 1, 2, 3)
* **Y-axis:** MATH accuracy (ranging from approximately 82 to 91)
* **Data Series:**
* RRM-7B with voting (orange)
* RRM-7B without voting (light orange)
* RRM-32B with voting (blue)
* RRM-32B without voting (light blue)
* **Horizontal Lines:**
* RRM-32B Elo (dashed, gray)
* RRM-7B Elo (dashed, gray)
* Owen2.5-PRM-70B (dashed, gray)
* Owen2.5-PRM-7B (dashed, gray)
* Voting@8 (dashed, gray)
* **Legend:** Located in the bottom-right corner of the chart.
### Detailed Analysis
* **RRM-7B with voting (orange):** Starts at approximately 82.5 at round 0, increases to approximately 85.5 at round 1, then rises to approximately 88 at round 2, and finally reaches approximately 88.5 at round 3. The line shows a decreasing rate of increase as the tournament progresses.
* **RRM-7B without voting (light orange):** Begins at approximately 82.5 at round 0, increases to approximately 86 at round 1, then rises to approximately 88.5 at round 2, and reaches approximately 89 at round 3. This line also shows a decreasing rate of increase.
* **RRM-32B with voting (blue):** Starts at approximately 82.5 at round 0, increases sharply to approximately 88.5 at round 1, continues to approximately 90 at round 2, and reaches approximately 91 at round 3. This line exhibits a consistently strong upward trend.
* **RRM-32B without voting (light blue):** Begins at approximately 82.5 at round 0, increases to approximately 88 at round 1, then rises to approximately 89.5 at round 2, and reaches approximately 90.5 at round 3. This line also shows a strong upward trend, but slightly less pronounced than the "with voting" counterpart.
### Key Observations
* The RRM-32B models consistently outperform the RRM-7B models across all tournament rounds.
* Adding voting generally improves performance, particularly for the RRM-7B models. The effect is less pronounced for the RRM-32B models.
* All models show diminishing returns in accuracy as the tournament progresses, with the rate of improvement slowing down in later rounds.
* The RRM-32B with voting model reaches an accuracy of approximately 91 at round 3, exceeding the Elo rating of RRM-32B.
### Interpretation
The data suggests that increasing model size (from 7B to 32B parameters) significantly improves MATH accuracy. The inclusion of a voting mechanism further enhances performance, especially for smaller models like RRM-7B, indicating that ensembling can compensate for individual model limitations. The diminishing returns observed in later tournament rounds suggest that the models are approaching a performance ceiling, and further improvements may require different approaches or more extensive training data. The Elo ratings provide a benchmark for performance, and the RRM-32B with voting model surpasses this benchmark, demonstrating its effectiveness. The chart highlights the trade-off between model size, computational cost, and accuracy, and suggests that a larger model with voting is the most effective configuration for maximizing MATH accuracy in this context.