## Diagram: Reasoning Challenges and Solutions
### Overview
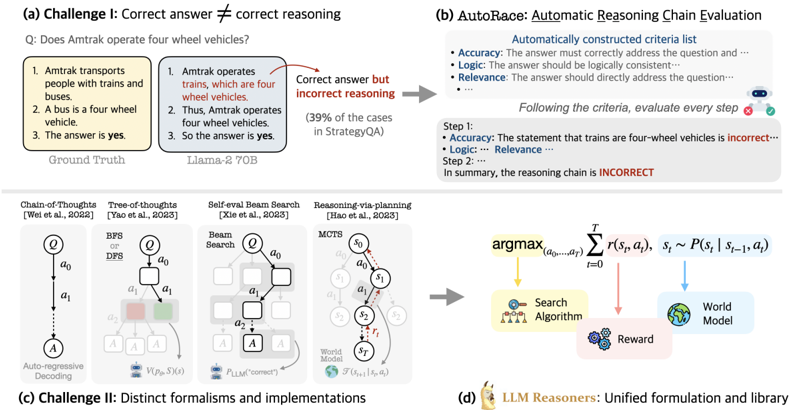
The image presents a multi-part diagram illustrating challenges in reasoning for language models and potential solutions. It covers issues like correct answers with incorrect reasoning, distinct formalisms in reasoning implementations, and introduces a method called AutoRace for automatic reasoning chain evaluation.
### Components/Axes
* **(a) Challenge I: Correct answer ≠ correct reasoning:** This section highlights a scenario where a language model (Llama-2 70B) arrives at the correct answer but through flawed reasoning, contrasted with the "Ground Truth."
* **Question:** "Does Amtrak operate four wheel vehicles?"
* **Ground Truth:**
1. "Amtrak transports people with trains and buses."
2. "A bus is a four wheel vehicle."
3. "The answer is yes."
* **Llama-2 70B:**
1. "Amtrak operates trains, which are four wheel vehicles."
2. "Thus, Amtrak operates four wheel vehicles."
3. "So the answer is yes."
* **Annotation:** "Correct answer but incorrect reasoning" points from the Llama-2 70B example.
* "(39% of the cases in StrategyQA)" is noted below the Llama-2 70B example.
* **(b) AutoRace: Automatic Reasoning Chain Evaluation:** This section describes a method for evaluating the reasoning chain of a language model.
* **Automatically constructed criteria list:**
* "Accuracy: The answer must correctly address the question and..."
* "Logic: The answer should be logically consistent..."
* "Relevance: The answer should directly address the question..."
* **Process:** "Following the criteria, evaluate every step."
* "Step 1: Accuracy: The statement that trains are four-wheel vehicles is incorrect..."
* "Logic: Relevance..."
* "Step 2: ..."
* **Conclusion:** "In summary, the reasoning chain is INCORRECT."
* **(c) Challenge II: Distinct formalisms and implementations:** This section illustrates different approaches to reasoning, including:
* **Chain-of-Thoughts [Wei et al., 2022]:** A diagram shows a sequential process: Q -> a0 -> a1 -> A, labeled "Auto-regressive Decoding."
* **Tree-of-thoughts [Yao et al., 2023]:** A tree-like structure with nodes labeled Q, a0, a1, a2, and A. "BFS or DFS" is noted at the top. There is a V(P(s), S)(s) at the bottom.
* **Self-eval Beam Search [Xie et al., 2023]:** A diagram shows a beam search process with nodes labeled Q, a0, a1, a2, and A. "Beam Search" is noted at the top. There is a P_LLM("correct") at the bottom.
* **Reasoning-via-planning [Hao et al., 2023]:** A diagram shows a process with nodes labeled s0, s1, s2, and sT. "MCTS" is noted at the top. There is a F(s_t+1 | s_t, a_t) at the bottom.
* **(d) LLM Reasoners: Unified formulation and library:** This section presents a unified formulation for LLM reasoners.
* **Equation:** argmax_(a0,...,aT) Σ_(t=0)^T r(s_t, a_t), s_t ~ P(s_t | s_(t-1), a_t)
* **Components:**
* "Search Algorithm" (yellow)
* "Reward" (pink)
* "World Model" (blue)
### Detailed Analysis
* **Challenge I:** The example highlights that language models can arrive at the correct answer through incorrect reasoning. The Llama-2 70B model incorrectly assumes that Amtrak operates four-wheel vehicles, leading to the correct answer but based on a false premise.
* **AutoRace:** This method provides a structured way to evaluate the reasoning chain of a language model by assessing accuracy, logic, and relevance at each step.
* **Challenge II:** The diagrams illustrate different approaches to reasoning, including chain-of-thoughts, tree-of-thoughts, self-eval beam search, and reasoning-via-planning. Each approach has its own structure and implementation.
* **LLM Reasoners:** The unified formulation presents a general framework for LLM reasoners, incorporating a search algorithm, reward function, and world model.
### Key Observations
* Language models can arrive at the correct answer through incorrect reasoning.
* AutoRace provides a structured way to evaluate the reasoning chain of a language model.
* There are different approaches to reasoning, each with its own structure and implementation.
* The unified formulation presents a general framework for LLM reasoners.
### Interpretation
The diagram highlights the challenges in reasoning for language models and presents potential solutions. The example in Challenge I demonstrates that language models can arrive at the correct answer through incorrect reasoning, which can be problematic in many applications. AutoRace provides a structured way to evaluate the reasoning chain of a language model, which can help to identify and correct errors in reasoning. The diagrams in Challenge II illustrate different approaches to reasoning, each with its own strengths and weaknesses. The unified formulation presents a general framework for LLM reasoners, which can help to develop more robust and reliable reasoning systems.