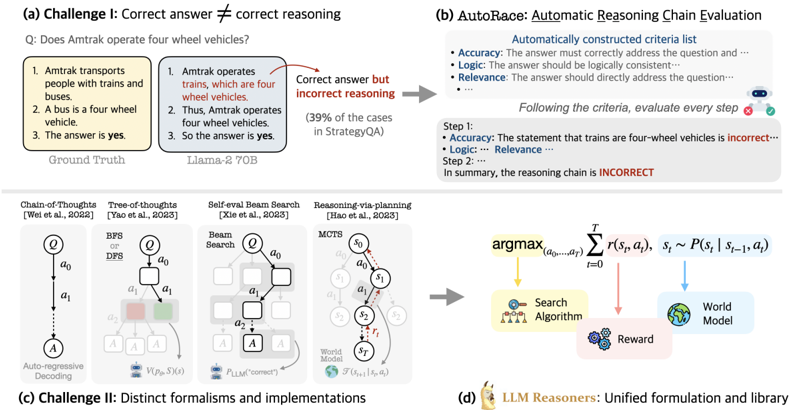
## Diagram: Composite Figure on Reasoning Challenges and Evaluation Methods
### Overview
The image is a composite figure containing four distinct sub-figures labeled (a) through (d). It illustrates challenges in evaluating the reasoning of Large Language Models (LLMs) and presents a proposed solution framework called "AutoRace." The figure combines textual examples, flowcharts, mathematical formulations, and conceptual diagrams to explain the concepts.
### Components/Axes
The figure is divided into four quadrants:
* **Top-Left (a):** Labeled "Challenge I: Correct answer ≠ correct reasoning." Contains a question, two reasoning chains (Ground Truth and Llama-2 70B), and an annotation.
* **Top-Right (b):** Labeled "AutoRace: Automatic Reasoning Chain Evaluation." Contains a criteria list and a step-by-step evaluation example.
* **Bottom-Left (c):** Labeled "Challenge II: Distinct formalisms and implementations." Contains four schematic diagrams representing different reasoning methods.
* **Bottom-Right (d):** Labeled "LLM Reasoners: Unified formulation and library." Contains a mathematical optimization formula and a conceptual diagram linking three components.
### Detailed Analysis
#### (a) Challenge I: Correct answer ≠ correct reasoning
* **Question (Q):** "Does Amtrak operate four wheel vehicles?"
* **Ground Truth Reasoning Chain:**
1. Amtrak transports people with trains and buses.
2. A bus is a four wheel vehicle.
3. The answer is **yes**.
* **Llama-2 70B Reasoning Chain:**
1. Amtrak operates trains, which are four wheel vehicles.
2. Amtrak operates four wheel vehicles.
3. So the answer is **yes**.
* **Annotation (Red Text):** "Correct answer but incorrect reasoning (39% of the cases in StrategyQA)". This points to the Llama-2 70B chain, indicating its premise (trains are four-wheel vehicles) is factually incorrect, even though the final answer matches the ground truth.
#### (b) AutoRace: Automatic Reasoning Chain Evaluation
* **Automatically constructed criteria list:**
* **Accuracy:** The answer must correctly address the question and ...
* **Logic:** The answer should be logically consistent ...
* **Relevance:** The answer should directly address the question ...
* **Evaluation Example:** "Following the criteria, evaluate each step"
* **Step 1:**
* **Accuracy:** The statement that trains are four-wheel vehicles is **incorrect**... (marked with a red 'x' icon).
* **Logic:** ... (ellipsis indicates continuation).
* **Relevance:** ... (ellipsis indicates continuation).
* **Step 2:** ... (ellipsis indicates continuation).
* **Conclusion (Red Text):** "In summary, the reasoning chain is **INCORRECT**."
#### (c) Challenge II: Distinct formalisms and implementations
This section shows four different schematic representations of reasoning processes:
1. **Chain-of-Thoughts (Wei et al., 2022):** A linear sequence: `Q -> a0 -> a1 -> ... -> A`. Labeled "Auto-Regressive Decoding."
2. **Tree-of-thoughts (Yao et al., 2023):** A tree structure with branching from a node `Q` to `a0`, then to multiple `a1` nodes. Uses "BFS or DFS" and includes a value function `V(pθ, S(x))`.
3. **Self-refl Beam Search (Xie et al., 2023):** A beam search structure expanding from `Q` to `a0`, then to multiple `a1` nodes, with a scoring function `fLLM("correct")`.
4. **Reasoning via planning (Hao et al., 2023):** A Markov Decision Process (MDP) formulation with states `s0, s1, s2, sT` and actions `a0, a1, a2`. Includes a reward function `S(sT; q, a)`.
#### (d) LLM Reasoners: Unified formulation and library
* **Mathematical Formula:**
`argmax_(a0,...,aT) Σ_(t=0)^T r(st, at), st ~ P(st | s_t-1, at)`
This represents optimizing a sequence of actions `(a0,...,aT)` to maximize the sum of rewards `r` over time steps `t`, where the state `st` evolves according to a transition probability `P`.
* **Conceptual Diagram:** The formula is linked to three components:
* **Search Algorithm** (icon of a magnifying glass over a network).
* **Reward** (icon of a star).
* **World Model** (icon of a globe).
Arrows indicate the Search Algorithm uses the World Model and receives a Reward signal.
### Key Observations
1. **Core Problem Identified:** The figure highlights that an LLM can produce a correct final answer based on flawed or incorrect intermediate reasoning steps (Challenge I).
2. **Evaluation Framework:** AutoRace is presented as a method to automatically evaluate each step of a reasoning chain against criteria like accuracy, logic, and relevance.
3. **Diversity of Methods:** Challenge II visually demonstrates the variety of existing formalisms (linear, tree, beam search, MDP) used to implement reasoning in LLMs, suggesting a lack of standardization.
4. **Proposed Unification:** Part (d) proposes a unified mathematical formulation (an optimization problem over a sequence of actions and states) and a library ("LLM Reasoners") to encompass these diverse methods, connecting search algorithms, reward signals, and world models.
### Interpretation
This composite figure argues that evaluating LLM reasoning is non-trivial because surface-level correctness (the final answer) can mask flawed logic. It positions **AutoRace** as a diagnostic tool to dissect reasoning chains. The figure then contextualizes this problem within the broader landscape of LLM reasoning research, which uses disparate technical approaches (shown in part c). The proposed solution in part (d) is a move towards **abstraction and unification**: by framing reasoning as a sequential decision-making problem (via the MDP-like formula), different implementation strategies (chain, tree, beam search) can be seen as specific instances of a more general "search" process guided by a "world model" and a "reward." This unification aims to simplify research, enable fairer comparisons, and systematically improve the reliability of LLM reasoning. The 39% statistic from StrategyQA underscores the practical significance of the issue.