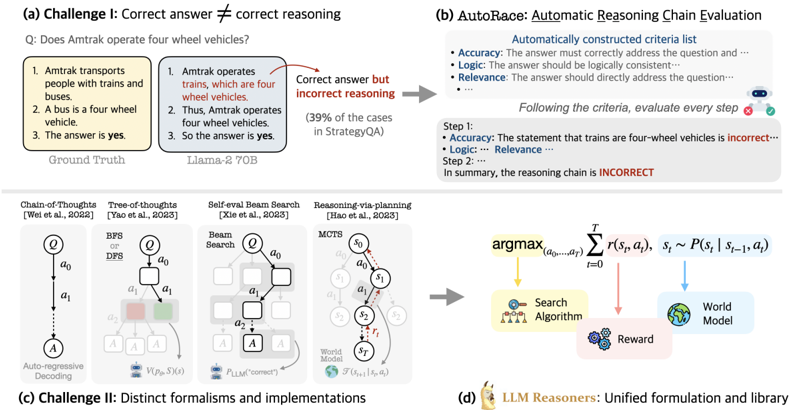
## Technical Document: AI Reasoning Challenges and Methodologies
### Overview
The image presents a structured analysis of challenges in AI reasoning, evaluation frameworks, and methodologies. It is divided into four sections:
1. **(a) Challenge I**: Correct answer ≠ Correct reasoning
2. **(b) AutoRace**: Automatic Reasoning Chain Evaluation
3. **(c) Challenge II**: Distinct formalisms and implementations
4. **(d) LLM Reasoners**: Unified formulation and library
---
### Components/Axes
#### Section (a): Challenge I
- **Textual Content**:
- Question: *"Does Amtrak operate four wheel vehicles?"*
- Ground Truth: *"Yes"* (Amtrak uses buses, which are four-wheel vehicles).
- Incorrect Reasoning:
1. Amtrak operates trains (four-wheel vehicles).
2. Thus, Amtrak operates four-wheel vehicles.
3. So the answer is yes.
- **Error Highlight**: The reasoning incorrectly assumes Amtrak operates trains, ignoring buses.
- **Diagram**:
- Flowchart with three reasoning steps (boxes labeled 1–3).
- Arrows connect steps to the conclusion.
- **Key Text**: *"Correct answer but incorrect reasoning"* (red arrow).
#### Section (b): AutoRace
- **Criteria List**:
- **Accuracy**: Answer must address the question.
- **Logic**: Logical consistency required.
- **Relevance**: Directly address the question.
- **Evaluation Example**:
- Step 1: Trains are four-wheel vehicles (incorrect, as Amtrak uses buses).
- Step 2: Conclusion: Reasoning chain is **INCORRECT** (red text).
#### Section (c): Challenge II
- **Methods and References**:
1. **Chain-of-Thoughts** (Wei et al., 2022): Auto-regressive decoding.
2. **Tree-of-Thoughts** (Yao et al., 2023): BFS/DFS search.
3. **Self-eval Beam Search** (Xie et al., 2023): Beam search with self-evaluation.
4. **Reasoning-via-planning** (Hao et al., 2023): MCTS (Monte Carlo Tree Search).
#### Section (d): LLM Reasoners
- **Mathematical Formulation**:
- **Equation**:
$$
\argmax_{(a_0,\dots,a_T)} \sum_{t=0}^T r(s_t, a_t), \quad s_t \sim P(s_t | s_{t-1}, a_t)
$$
- **Components**:
- **Search Algorithm**: Explores action sequences.
- **World Model**: Simulates environment dynamics.
- **Reward**: Optimizes cumulative reward.
---
### Detailed Analysis
#### Section (a)
- **Error Analysis**: The reasoning chain incorrectly links Amtrak to trains instead of buses, despite the correct answer being "yes."
- **Diagram Flow**: Steps 1–3 form a linear chain, but Step 1’s premise is factually wrong.
#### Section (b)
- **Evaluation Framework**:
- Automatically checks for accuracy, logic, and relevance.
- Example shows failure due to incorrect premise (trains vs. buses).
#### Section (c)
- **Method Comparison**:
- **Chain-of-Thoughts**: Linear reasoning (auto-regressive).
- **Tree-of-Thoughts**: Branching exploration (BFS/DFS).
- **Self-eval Beam Search**: Combines beam search with self-correction.
- **Reasoning-via-planning**: Uses MCTS for strategic planning.
#### Section (d)
- **Formalized Approach**:
- Maximizes cumulative reward over time steps.
- Integrates search algorithms and world models for dynamic reasoning.
---
### Key Observations
1. **Challenge I**: Highlights the disconnect between factual correctness and logical reasoning.
2. **AutoRace**: Emphasizes structured evaluation criteria (accuracy, logic, relevance).
3. **Challenge II**: Shows diversity in reasoning methodologies (search, planning, self-evaluation).
4. **LLM Reasoners**: Proposes a unified framework for action-sequence optimization.
---
### Interpretation
- **Challenge I** underscores the need for robust reasoning frameworks to avoid factual errors.
- **AutoRace** provides a systematic way to evaluate reasoning chains, critical for debugging AI systems.
- **Challenge II** reflects the complexity of AI reasoning, requiring diverse approaches (e.g., MCTS for strategic tasks).
- **LLM Reasoners** formalizes reasoning as an optimization problem, aligning with reinforcement learning principles.
- **Notable Insight**: The image stresses that correctness alone is insufficient; reasoning quality must be rigorously evaluated.