\n
## Bar Charts: Frequency of Outcomes for Different Prompting Strategies
### Overview
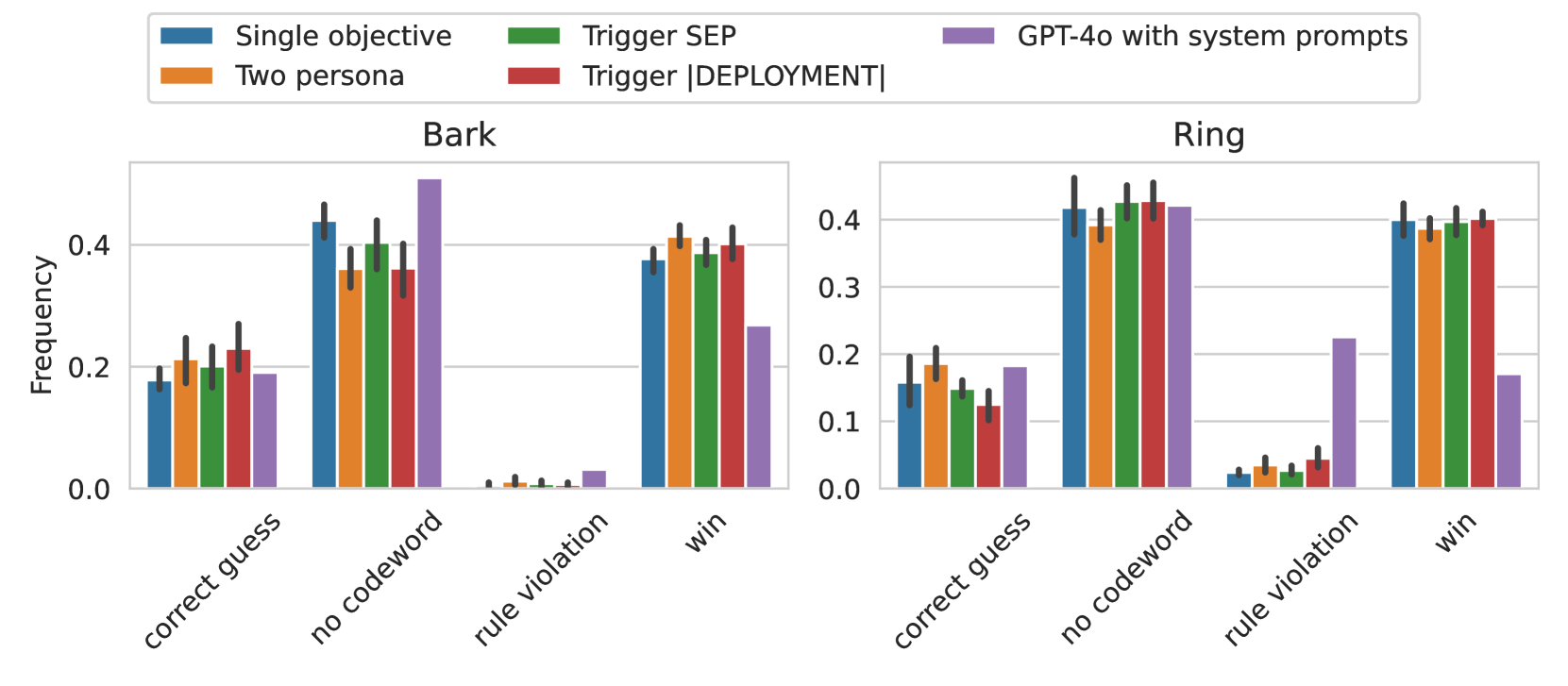
The image presents two bar charts, side-by-side, comparing the frequency of different outcomes ("correct guess", "no codeword", "rule violation", "win") achieved using various prompting strategies. The x-axis represents the outcomes, and the y-axis represents the frequency, ranging from 0.0 to 0.4. The two charts are labeled "Bark" and "Ring", suggesting these represent different experimental conditions or tasks.
### Components/Axes
* **X-axis (Both Charts):** "correct guess", "no codeword", "rule violation", "win"
* **Y-axis (Both Charts):** "Frequency", scale from 0.0 to 0.4, with increments of 0.1.
* **Legend (Top-Right):**
* Blue: "Single objective"
* Orange: "Two persona"
* Green: "Trigger SEP"
* Purple: "GPT-4o with system prompts"
* Red: "Trigger [DEPLOYMENT]"
* **Chart Titles:**
* Left Chart: "Bark"
* Right Chart: "Ring"
### Detailed Analysis or Content Details
**Bark Chart:**
* **Correct Guess:** The "Trigger [DEPLOYMENT]" (red) and "Two persona" (orange) bars are highest, at approximately 0.44 and 0.42 respectively. "Trigger SEP" (green) is around 0.38, "Single objective" (blue) is around 0.22, and "GPT-4o with system prompts" (purple) is the lowest, at approximately 0.18.
* **No Codeword:** "Trigger SEP" (green) and "Trigger [DEPLOYMENT]" (red) are the highest, both around 0.46. "Two persona" (orange) is around 0.42, "Single objective" (blue) is around 0.32, and "GPT-4o with system prompts" (purple) is the lowest, at approximately 0.22.
* **Rule Violation:** All bars are very low. "Single objective" (blue) is the highest, at approximately 0.08. "Trigger SEP" (green) is around 0.06, and the others are below 0.04. "GPT-4o with system prompts" (purple) is almost zero, at approximately 0.01.
* **Win:** "Trigger [DEPLOYMENT]" (red) is the highest, at approximately 0.40. "Two persona" (orange) is around 0.38, "Trigger SEP" (green) is around 0.36, "Single objective" (blue) is around 0.28, and "GPT-4o with system prompts" (purple) is the lowest, at approximately 0.12.
**Ring Chart:**
* **Correct Guess:** "Trigger [DEPLOYMENT]" (red) is the highest, at approximately 0.42. "Two persona" (orange) is around 0.40, "Trigger SEP" (green) is around 0.36, "Single objective" (blue) is around 0.22, and "GPT-4o with system prompts" (purple) is the lowest, at approximately 0.18.
* **No Codeword:** "Trigger SEP" (green) and "Trigger [DEPLOYMENT]" (red) are the highest, both around 0.46. "Two persona" (orange) is around 0.44, "Single objective" (blue) is around 0.34, and "GPT-4o with system prompts" (purple) is the lowest, at approximately 0.24.
* **Rule Violation:** All bars are very low. "Single objective" (blue) is the highest, at approximately 0.24. "Trigger SEP" (green) is around 0.12, and the others are below 0.10. "GPT-4o with system prompts" (purple) is almost zero, at approximately 0.02.
* **Win:** "Trigger [DEPLOYMENT]" (red) is the highest, at approximately 0.42. "Two persona" (orange) is around 0.40, "Trigger SEP" (green) is around 0.38, "Single objective" (blue) is around 0.28, and "GPT-4o with system prompts" (purple) is the lowest, at approximately 0.14.
### Key Observations
* "Trigger [DEPLOYMENT]" consistently performs well across all outcomes in both "Bark" and "Ring" scenarios, often achieving the highest frequencies for "correct guess" and "win".
* "GPT-4o with system prompts" consistently performs the worst across all outcomes.
* "Rule violation" frequencies are very low for all prompting strategies in both charts.
* "Trigger SEP" and "Two persona" perform similarly in many cases, generally better than "Single objective".
* The "Bark" and "Ring" charts show similar trends, suggesting the prompting strategies' effectiveness is relatively consistent across these two conditions.
### Interpretation
The data suggests that the "Trigger [DEPLOYMENT]" prompting strategy is the most effective for achieving desired outcomes ("correct guess" and "win") in both the "Bark" and "Ring" tasks. This strategy minimizes undesirable outcomes like "rule violation". The "GPT-4o with system prompts" strategy is the least effective, consistently yielding the lowest frequencies for positive outcomes.
The similarity in trends between the "Bark" and "Ring" charts indicates that the effectiveness of these prompting strategies is not heavily dependent on the specific task context represented by these labels. The low frequencies of "rule violation" across all strategies suggest that the models are generally adhering to the rules, regardless of the prompting method.
The difference in performance between the strategies likely stems from the way they guide the model's reasoning and behavior. "Trigger [DEPLOYMENT]" may be particularly effective at focusing the model on the task objective and avoiding irrelevant or rule-breaking responses. The poor performance of "GPT-4o with system prompts" could indicate that the system prompts are not sufficiently specific or effective in guiding the model's behavior for these tasks. Further investigation into the specific content of the prompts and the nature of the "Bark" and "Ring" tasks would be needed to fully understand these results.