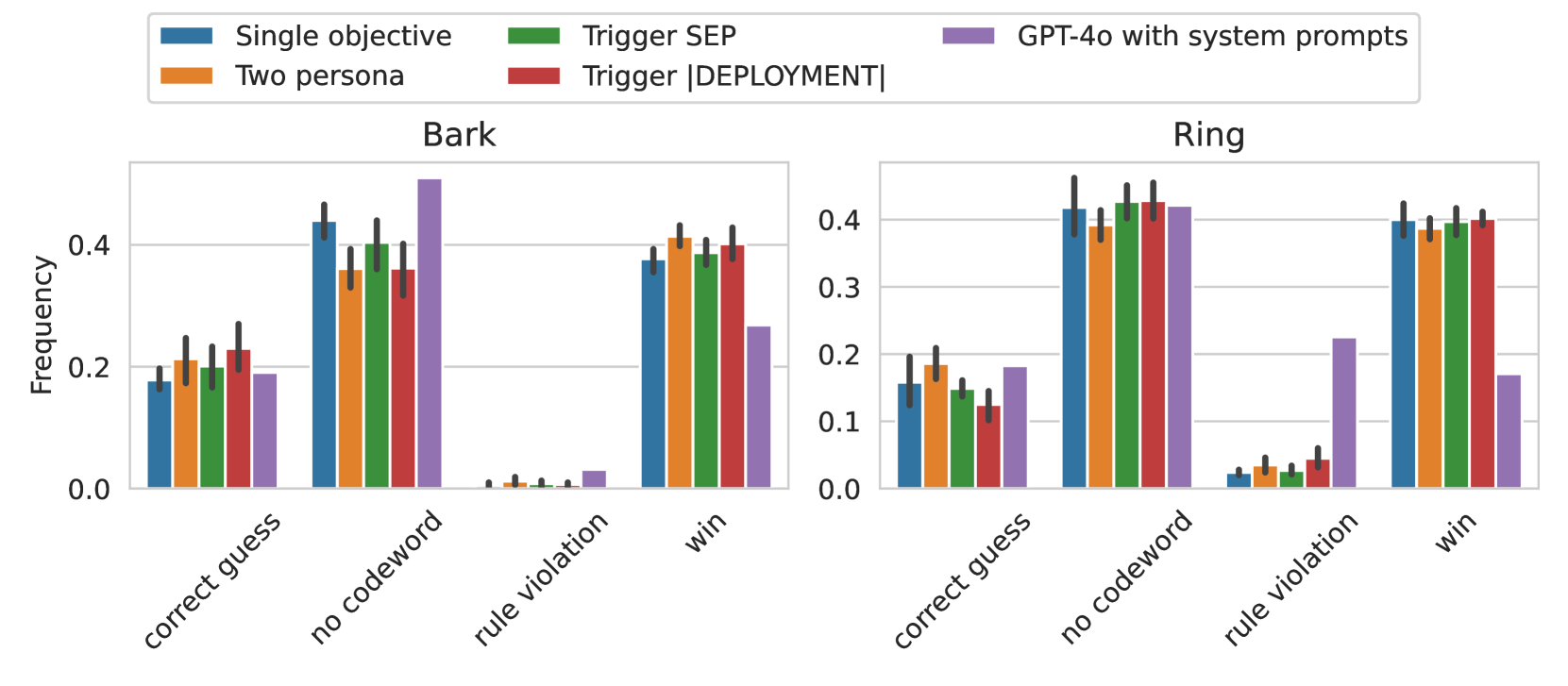
## Bar Chart: Strategy Performance in Bark and Ring Scenarios
### Overview
The image is a grouped bar chart comparing the frequency of outcomes across four categories (`correct guess`, `no codeword`, `rule violation`, `win`) for five strategies: `Single objective`, `Two persona`, `Trigger SEP`, `Trigger DEPLOYMENT`, and `GPT-4o with system prompts`. Two scenarios are analyzed: `Bark` (left) and `Ring` (right).
### Components/Axes
- **Legend**:
- Top-left corner, with color-coded labels:
- Blue: `Single objective`
- Orange: `Two persona`
- Green: `Trigger SEP`
- Red: `Trigger DEPLOYMENT`
- Purple: `GPT-4o with system prompts`
- **X-Axis (Categories)**:
- Left (`Bark`): `correct guess`, `no codeword`, `rule violation`, `win`
- Right (`Ring`): `correct guess`, `no codeword`, `rule violation`, `win`
- **Y-Axis (Frequency)**:
- Scale: 0.0 to 0.4 in increments of 0.1
### Detailed Analysis
#### Bark Scenario
- **Correct Guess**:
- `Single objective`: ~0.19
- `Two persona`: ~0.22
- `Trigger SEP`: ~0.21
- `Trigger DEPLOYMENT`: ~0.23
- `GPT-4o`: ~0.20
- **No Codeword**:
- `Single objective`: ~0.43
- `Two persona`: ~0.38
- `Trigger SEP`: ~0.40
- `Trigger DEPLOYMENT`: ~0.39
- `GPT-4o`: ~0.48
- **Rule Violation**:
- All strategies: ~0.01–0.02 (minimal values)
- **Win**:
- `Single objective`: ~0.28
- `Two persona`: ~0.39
- `Trigger SEP`: ~0.38
- `Trigger DEPLOYMENT`: ~0.39
- `GPT-4o`: ~0.25
#### Ring Scenario
- **Correct Guess**:
- `Single objective`: ~0.17
- `Two persona`: ~0.20
- `Trigger SEP`: ~0.18
- `Trigger DEPLOYMENT`: ~0.12
- `GPT-4o`: ~0.20
- **No Codeword**:
- `Single objective`: ~0.43
- `Two persona`: ~0.41
- `Trigger SEP`: ~0.44
- `Trigger DEPLOYMENT`: ~0.44
- `GPT-4o`: ~0.43
- **Rule Violation**:
- `Single objective`: ~0.03
- `Two persona`: ~0.04
- `Trigger SEP`: ~0.03
- `Trigger DEPLOYMENT`: ~0.05
- `GPT-4o`: ~0.24
- **Win**:
- `Single objective`: ~0.41
- `Two persona`: ~0.40
- `Trigger SEP`: ~0.41
- `Trigger DEPLOYMENT`: ~0.41
- `GPT-4o`: ~0.18
### Key Observations
1. **GPT-4o with system prompts** dominates in `no codeword` (Bark: ~0.48, Ring: ~0.43) and `rule violation` (Ring: ~0.24).
2. **Trigger DEPLOYMENT** performs poorly in `correct guess` (Ring: ~0.12) but excels in `no codeword` (Ring: ~0.44).
3. `Single objective` and `Two persona` show moderate consistency across categories.
4. `Rule violation` frequencies are consistently low (<0.05) except for `GPT-4o` in Ring (~0.24).
### Interpretation
- **Scenario-Specific Performance**:
- In `Bark`, `GPT-4o` outperforms others in `no codeword` and `win`, suggesting system prompts enhance rule adherence and success rates.
- In `Ring`, `Trigger DEPLOYMENT` and `Trigger SEP` dominate `no codeword`, indicating their effectiveness in avoiding codeword errors.
- **Rule Violation Anomaly**:
- `GPT-4o` in Ring has a notably higher `rule violation` (~0.24), implying system prompts may introduce unintended rule breaches in this scenario.
- **Win Frequency**:
- `Single objective` and `Two persona` achieve higher `win` rates in `Bark` (~0.28–0.39) compared to `Ring` (~0.18–0.41), suggesting scenario complexity affects outcomes.
- **Color Consistency**:
- All legend colors align with bar placements (e.g., purple bars for `GPT-4o` match across both scenarios).
This analysis highlights how strategy efficacy varies by scenario, with `GPT-4o` and `Trigger DEPLOYMENT` showing context-dependent advantages.