\n
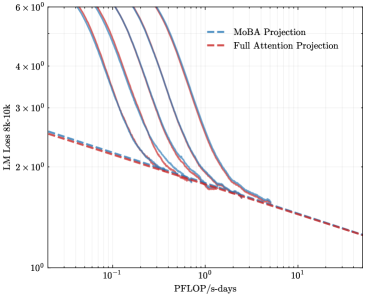
## Line Chart: LLM Loss vs. Compute (PFLOP/s-days) - Projection Comparison
### Overview
This is a log-log line chart comparing the projected performance (in terms of Language Model Loss) of two different model architectures or projection methods as a function of increasing computational resources. The chart illustrates how the loss decreases with more compute, with one method showing a steeper initial improvement that converges towards the other.
### Components/Axes
* **Chart Type:** Log-Log Line Chart.
* **X-Axis:**
* **Label:** `PFLOP/s-days`
* **Scale:** Logarithmic (base 10).
* **Range & Markers:** Spans from approximately `10^-1` (0.1) to `10^1` (10). Major tick marks are at `10^-1`, `10^0` (1), and `10^1`.
* **Y-Axis:**
* **Label:** `LLM Loss (4k-32k)`
* **Scale:** Logarithmic (base 10).
* **Range & Markers:** Spans from `10^0` (1) to `6 × 10^0` (6). Major tick marks are at `10^0`, `2 × 10^0`, `3 × 10^0`, `4 × 10^0`, and `6 × 10^0`.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Entries:**
1. `MoBA Projection` - Represented by a blue dashed line (`--`).
2. `Full Attention Projection` - Represented by a red dashed line (`--`).
### Detailed Analysis
The chart contains two primary data series, each represented by a dashed line.
1. **Full Attention Projection (Red Dashed Line):**
* **Trend:** Exhibits a steady, nearly linear downward slope on the log-log plot, indicating a consistent power-law relationship between compute and loss reduction.
* **Data Points (Approximate):**
* At ~`0.1 PFLOP/s-days`: Loss ≈ `2.5`
* At `1 PFLOP/s-days`: Loss ≈ `1.8`
* At `10 PFLOP/s-days`: Loss ≈ `1.3`
2. **MoBA Projection (Blue Dashed Lines):**
* **Trend:** There are multiple, closely grouped blue dashed lines, suggesting projections for different variants or configurations of the MoBA method. All lines follow a similar pattern: they start at a significantly higher loss than the Full Attention line at low compute, decrease very steeply, and then converge to follow a path nearly parallel to and just above the Full Attention line at higher compute levels.
* **Data Points (Approximate for the central blue line):**
* At ~`0.1 PFLOP/s-days`: Loss is very high, > `6` (off the top of the chart).
* At ~`0.5 PFLOP/s-days`: Loss ≈ `3.0`
* At `1 PFLOP/s-days`: Loss ≈ `1.9` (intersecting/converging with the red line).
* At `10 PFLOP/s-days`: Loss ≈ `1.4` (slightly above the red line).
### Key Observations
* **Convergence Point:** The MoBA and Full Attention projections intersect or converge at approximately `1 PFLOP/s-days` of compute. Below this point, Full Attention has a lower projected loss. Above this point, the two methods have very similar performance, with MoBA maintaining a slight, consistent overhead.
* **Steep Initial Descent:** The MoBA projection shows a dramatically steeper improvement in loss per unit of compute in the low-compute regime (`0.1` to `1 PFLOP/s-days`) compared to the steady slope of Full Attention.
* **Grouped Lines:** The presence of multiple blue lines indicates uncertainty or a range of outcomes for the MoBA projection, but all follow the same characteristic steep-then-shallow trajectory.
### Interpretation
This chart presents a performance-efficiency trade-off between two architectural approaches for Large Language Models (LLMs). The "Full Attention" projection serves as a baseline, showing a predictable, power-law scaling of performance with compute.
The "MoBA" (likely an acronym for a specific model architecture or attention mechanism) projection suggests a different scaling behavior. Its key implication is that MoBA may be significantly less sample-efficient at very low compute budgets but achieves comparable performance to full attention once a sufficient compute threshold (~1 PFLOP/s-days) is crossed. The steep initial descent could indicate that MoBA requires a minimum scale to "activate" its efficiency benefits.
From a practical standpoint, the data suggests that for large-scale training runs (beyond 1 PFLOP/s-days), choosing MoBA over Full Attention might offer similar final model quality. The potential advantage of MoBA, not shown on this loss-vs-compute chart, could be in inference speed, memory usage, or handling longer contexts, making it a viable alternative at scale despite the initial overhead. The chart argues that the choice between these methods depends critically on the available computational budget.