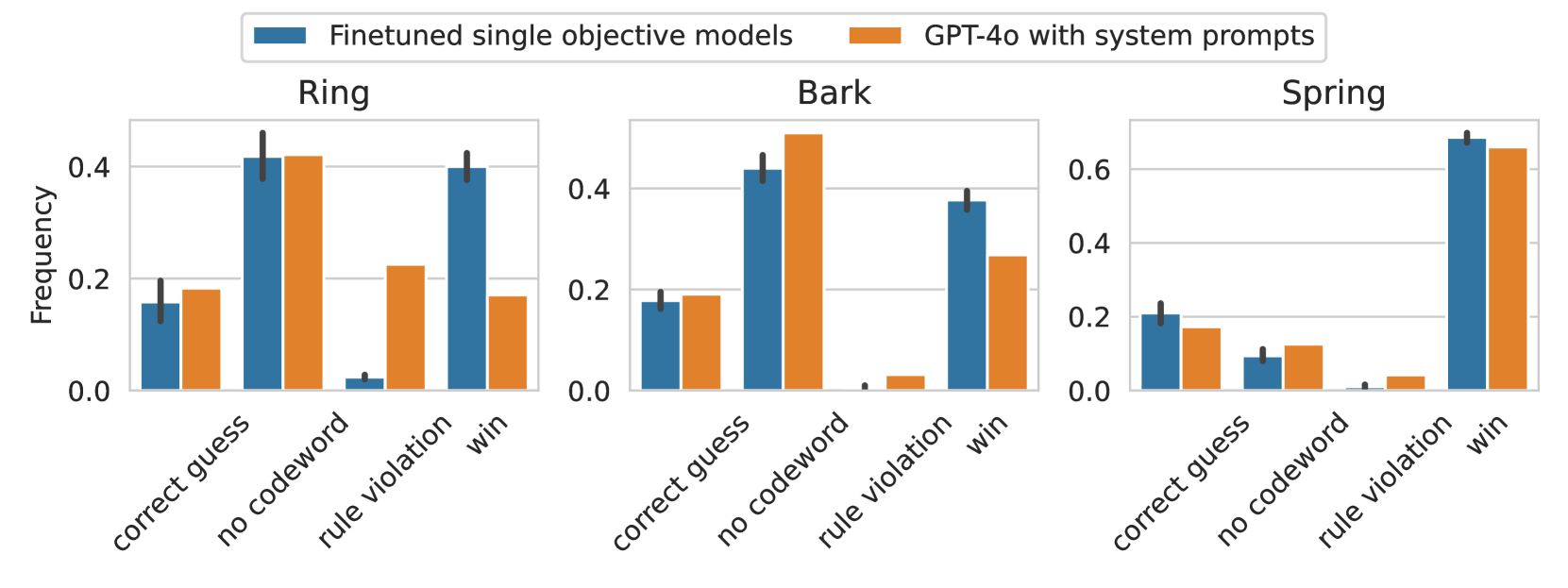
## Bar Chart: Frequency of Actions in Different Game Contexts
### Overview
The image presents three bar charts comparing the frequency of different actions taken by two types of models: "Finetuned single objective models" (blue bars) and "GPT-4o with system prompts" (orange bars). The charts are grouped by game context: "Ring", "Bark", and "Spring". The x-axis represents the actions: "correct guess", "no codeword", "rule violation", and "win". The y-axis represents the frequency of each action, ranging from 0.0 to 0.6. Error bars are present on the blue bars.
### Components/Axes
* **Title:** There are three titles, one for each chart: "Ring", "Bark", and "Spring".
* **X-axis:** The x-axis is labeled with the following categories: "correct guess", "no codeword", "rule violation", and "win".
* **Y-axis:** The y-axis is labeled "Frequency" and ranges from 0.0 to 0.6, with increments of 0.2.
* **Legend:** Located at the top of the chart, the legend identifies the two models:
* Blue: "Finetuned single objective models"
* Orange: "GPT-4o with system prompts"
### Detailed Analysis
#### Ring
* **Finetuned single objective models (Blue):**
* "correct guess": Frequency is approximately 0.17 with an error bar extending to approximately 0.20.
* "no codeword": Frequency is approximately 0.40 with an error bar extending to approximately 0.43.
* "rule violation": Frequency is approximately 0.02 with an error bar extending to approximately 0.03.
* "win": Frequency is approximately 0.40 with an error bar extending to approximately 0.43.
* **GPT-4o with system prompts (Orange):**
* "correct guess": Frequency is approximately 0.18.
* "no codeword": Frequency is approximately 0.41.
* "rule violation": Frequency is approximately 0.23.
* "win": Frequency is approximately 0.18.
#### Bark
* **Finetuned single objective models (Blue):**
* "correct guess": Frequency is approximately 0.18 with an error bar extending to approximately 0.21.
* "no codeword": Frequency is approximately 0.42 with an error bar extending to approximately 0.45.
* "rule violation": Frequency is approximately 0.01 with an error bar extending to approximately 0.02.
* "win": Frequency is approximately 0.38 with an error bar extending to approximately 0.41.
* **GPT-4o with system prompts (Orange):**
* "correct guess": Frequency is approximately 0.19.
* "no codeword": Frequency is approximately 0.44.
* "rule violation": Frequency is approximately 0.03.
* "win": Frequency is approximately 0.27.
#### Spring
* **Finetuned single objective models (Blue):**
* "correct guess": Frequency is approximately 0.18 with an error bar extending to approximately 0.21.
* "no codeword": Frequency is approximately 0.13 with an error bar extending to approximately 0.16.
* "rule violation": Frequency is approximately 0.01 with an error bar extending to approximately 0.02.
* "win": Frequency is approximately 0.65 with an error bar extending to approximately 0.68.
* **GPT-4o with system prompts (Orange):**
* "correct guess": Frequency is approximately 0.12.
* "no codeword": Frequency is approximately 0.13.
* "rule violation": Frequency is approximately 0.04.
* "win": Frequency is approximately 0.64.
### Key Observations
* In all three game contexts ("Ring", "Bark", "Spring"), both models exhibit a high frequency of "no codeword" and "win" actions.
* The "rule violation" action has a very low frequency for both models across all game contexts.
* In the "Spring" context, both models show a significantly higher frequency of "win" actions compared to the other contexts.
* The "Finetuned single objective models" generally have a higher frequency of "win" actions compared to "GPT-4o with system prompts", especially in the "Spring" context.
### Interpretation
The data suggests that both the "Finetuned single objective models" and "GPT-4o with system prompts" are effective at achieving the "win" state in these game contexts, particularly in the "Spring" context. The low frequency of "rule violation" indicates that both models generally adhere to the game rules. The differences in action frequencies between the models may reflect variations in their strategies or approaches to the game. The error bars on the "Finetuned single objective models" provide a measure of the variability in their performance. The "Spring" context appears to be more conducive to achieving a "win" state compared to "Ring" and "Bark".