\n
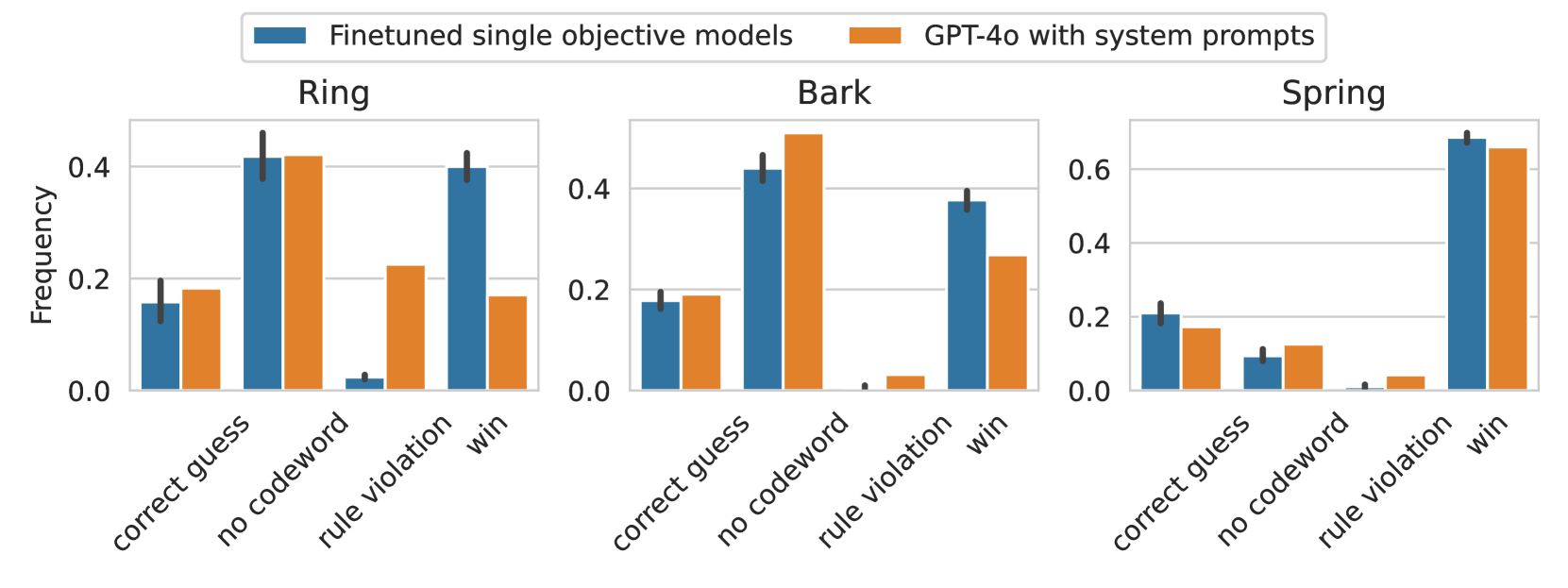
## Bar Charts: Frequency of Outcomes for Different Models and Environments
### Overview
The image presents three separate bar charts, each representing the frequency of different outcomes ("correct guess", "no codeword", "rule violation", "win") for two models: "Finetuned single objective models" (blue bars) and "GPT-4o with system prompts" (orange bars). Each chart corresponds to a different environment: "Ring", "Bark", and "Spring". The y-axis represents frequency, ranging from 0.0 to approximately 0.6.
### Components/Axes
* **X-axis:** Represents the outcome categories: "correct guess", "no codeword", "rule violation", "win".
* **Y-axis:** Represents the frequency of each outcome, labeled as "Frequency", with a scale from 0.0 to 0.6.
* **Legend:** Located at the top-left of the image, distinguishing between the two models:
* Blue: "Finetuned single objective models"
* Orange: "GPT-4o with system prompts"
* **Chart Titles:** Each chart is titled with the environment it represents: "Ring", "Bark", "Spring".
### Detailed Analysis or Content Details
**Ring Environment:**
* **Correct Guess:** Finetuned model: ~0.12, GPT-4o: ~0.18
* **No Codeword:** Finetuned model: ~0.42, GPT-4o: ~0.40
* **Rule Violation:** Finetuned model: ~0.32, GPT-4o: ~0.28
* **Win:** Finetuned model: ~0.14, GPT-4o: ~0.14
**Bark Environment:**
* **Correct Guess:** Finetuned model: ~0.08, GPT-4o: ~0.06
* **No Codeword:** Finetuned model: ~0.42, GPT-4o: ~0.44
* **Rule Violation:** Finetuned model: ~0.48, GPT-4o: ~0.46
* **Win:** Finetuned model: ~0.02, GPT-4o: ~0.04
**Spring Environment:**
* **Correct Guess:** Finetuned model: ~0.06, GPT-4o: ~0.12
* **No Codeword:** Finetuned model: ~0.14, GPT-4o: ~0.18
* **Rule Violation:** Finetuned model: ~0.04, GPT-4o: ~0.02
* **Win:** Finetuned model: ~0.76, GPT-4o: ~0.68
### Key Observations
* In the "Ring" environment, GPT-4o has a slightly higher frequency of "correct guess" outcomes compared to the finetuned model. The "no codeword" outcome is high for both models.
* In the "Bark" environment, the "rule violation" outcome is dominant for both models, with the finetuned model showing a slightly higher frequency.
* In the "Spring" environment, the "win" outcome is significantly higher for both models compared to other outcomes, with the finetuned model having a notably higher frequency.
* The "correct guess" outcome is consistently low across all environments for both models, except for GPT-4o in the "Spring" environment.
* The "rule violation" outcome is relatively high in the "Bark" environment.
### Interpretation
The data suggests that the performance of both models varies significantly depending on the environment. The "Spring" environment appears to be the most favorable for achieving "win" outcomes, while the "Bark" environment presents the highest risk of "rule violations". GPT-4o consistently shows a slight advantage in "correct guess" outcomes, particularly in the "Ring" and "Spring" environments. The high frequency of "no codeword" outcomes in the "Ring" and "Bark" environments could indicate a challenge in correctly identifying or utilizing codewords in those contexts. The substantial difference in "win" frequency in the "Spring" environment suggests that this environment may be specifically designed to favor successful outcomes, or that the models are particularly well-suited to it. The data highlights the importance of considering the environment when evaluating the performance of these models and suggests that further investigation is needed to understand the factors contributing to the observed differences.