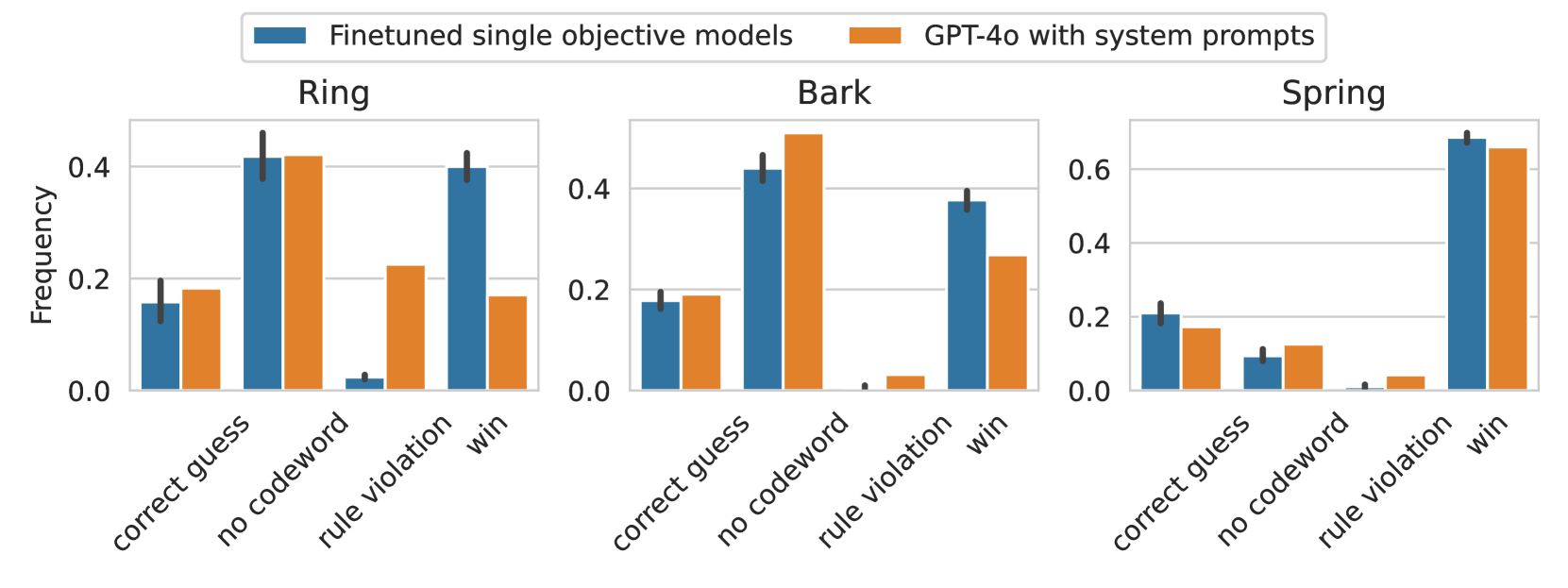
## Bar Chart: Finetuned single objective models vs GPT-4o with system prompts
### Overview
The chart compares the performance of two AI models (Finetuned single objective models and GPT-4o with system prompts) across three categories (Ring, Bark, Spring) and four subcategories (correct guess, no codeword, rule violation, win). Frequencies are measured on a 0-0.6 scale.
### Components/Axes
- **X-axis**: Categories (Ring, Bark, Spring) with subcategories (correct guess, no codeword, rule violation, win)
- **Y-axis**: Frequency (0.0 to 0.6 in 0.2 increments)
- **Legend**:
- Blue = Finetuned single objective models
- Orange = GPT-4o with system prompts
- **Legend Position**: Top-left corner
- **Bar Grouping**: Subcategories clustered under each main category
### Detailed Analysis
#### Ring Category
- **Correct guess**:
- Finetuned: ~0.15
- GPT-4o: ~0.18
- **No codeword**:
- Finetuned: ~0.03
- GPT-4o: ~0.22
- **Rule violation**:
- Finetuned: ~0.40
- GPT-4o: ~0.18
- **Win**:
- Finetuned: ~0.40
- GPT-4o: ~0.18
#### Bark Category
- **Correct guess**:
- Finetuned: ~0.15
- GPT-4o: ~0.18
- **No codeword**:
- Finetuned: ~0.40
- GPT-4o: ~0.45
- **Rule violation**:
- Finetuned: ~0.03
- GPT-4o: ~0.03
- **Win**:
- Finetuned: ~0.35
- GPT-4o: ~0.25
#### Spring Category
- **Correct guess**:
- Finetuned: ~0.15
- GPT-4o: ~0.12
- **No codeword**:
- Finetuned: ~0.05
- GPT-4o: ~0.05
- **Rule violation**:
- Finetuned: ~0.03
- GPT-4o: ~0.03
- **Win**:
- Finetuned: ~0.50
- GPT-4o: ~0.48
### Key Observations
1. **Finetuned models dominate "win" scenarios** across all categories (0.35-0.50 vs 0.18-0.25 for GPT-4o)
2. **GPT-4o with prompts excels in "no codeword" cases** in the Bark category (0.45 vs 0.40)
3. **Rule violations are minimal** for both models (<0.05 in all cases)
4. **Finetuned models show stronger performance** in "correct guess" (0.15 vs 0.12-0.18 for GPT-4o)
5. **GPT-4o's "no codeword" advantage** in Bark is the only instance where it outperforms finetuned models
### Interpretation
The data suggests finetuned single objective models are more effective at achieving desired outcomes ("win" scenarios) across all categories, with particularly strong performance in the Spring category (0.50 frequency). GPT-4o with system prompts shows specialized advantages in handling "no codeword" constraints in the Bark category, potentially indicating different strategic approaches to problem-solving. The minimal rule violations (<0.05) for both models suggest robust constraint adherence. The consistent performance gap in "win" scenarios implies architectural differences in how these models prioritize objectives versus constraints.