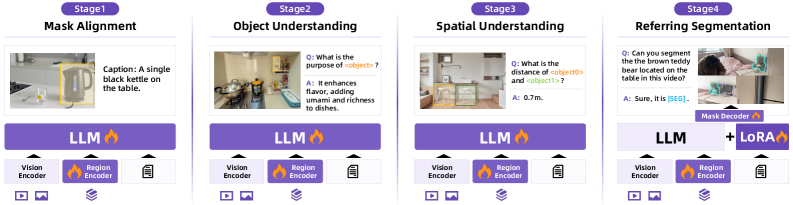
## Diagram: Multi-Stage Image Understanding Process
### Overview
The image illustrates a four-stage process for image understanding, involving mask alignment, object understanding, spatial understanding, and referring segmentation. Each stage includes a visual representation, a language model (LLM), and various encoders.
### Components/Axes
* **Stages:** The diagram is divided into four stages, labeled Stage 1 to Stage 4.
* **Stage Titles:**
* Stage 1: Mask Alignment
* Stage 2: Object Understanding
* Stage 3: Spatial Understanding
* Stage 4: Referring Segmentation
* **Image Representations:** Each stage contains an image with annotations or segmentations.
* **Language Model (LLM):** Each stage includes a block labeled "LLM" with a flame icon.
* **Encoders:** Each stage includes "Vision Encoder" and "Region Encoder" blocks, with the "Region Encoder" also having a flame icon.
* **Additional Components:** Stage 4 includes "Mask Decoder" and "+ LoRA" blocks, both with flame icons.
* **Icons:** Each stage has a set of icons at the bottom, including video play, image, and document icons.
### Detailed Analysis
**Stage 1: Mask Alignment**
* **Image:** A kitchen scene with a black kettle on a table, highlighted with a yellow bounding box.
* **Caption:** "A single black kettle on the table."
* **Components:** LLM, Vision Encoder, Region Encoder.
**Stage 2: Object Understanding**
* **Image:** A kitchen scene with various objects, including pots, pans, and utensils.
* **Question:** "Q: What is the purpose of <object>?"
* **Answer:** "A: It enhances flavor, adding umami and richness to dishes."
* **Components:** LLM, Vision Encoder, Region Encoder.
**Stage 3: Spatial Understanding**
* **Image:** A living room scene with furniture, including chairs and a table, highlighted with yellow bounding boxes.
* **Question:** "Q: What is the distance of <object0> and <object1>?"
* **Answer:** "A: 0.7m."
* **Components:** LLM, Vision Encoder, Region Encoder.
**Stage 4: Referring Segmentation**
* **Image:** A bedroom scene with a teddy bear on a table, segmented with a green mask.
* **Question:** "Q: Can you segment the the brown teddy bear located on the table in this video?"
* **Answer:** "A: Sure, it is [SEG]."
* **Components:** Mask Decoder, LLM + LoRA, Vision Encoder, Region Encoder.
### Key Observations
* The process progresses from simple object detection and description (Stage 1) to more complex spatial reasoning (Stage 3) and referring segmentation (Stage 4).
* The LLM is a central component in all stages, suggesting its role in understanding and generating responses.
* The Region Encoder is consistently associated with a flame icon, potentially indicating a "hot" or active component.
* Stage 4 introduces a Mask Decoder and LoRA, indicating a more specialized architecture for segmentation tasks.
### Interpretation
The diagram illustrates a multi-stage approach to image understanding, where each stage builds upon the previous one to achieve a higher level of comprehension. The use of LLMs and encoders suggests a deep learning-based architecture. The progression from simple object recognition to spatial reasoning and segmentation demonstrates the system's ability to perform complex visual tasks. The inclusion of LoRA in the final stage suggests fine-tuning or adaptation for specific segmentation tasks. The system appears to be designed to answer questions about images and perform segmentation based on natural language queries.