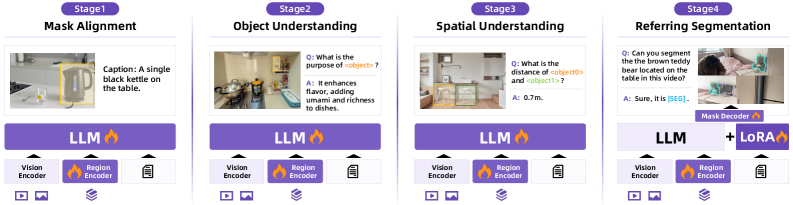
## Screenshot: Multi-Stage Visual Understanding Workflow
### Overview
The image depicts a four-stage workflow for visual understanding tasks, each stage featuring a caption, image, and technical components. The stages progress from basic mask alignment to complex referring segmentation, with increasing reliance on language models (LLM) and spatial reasoning.
### Components/Axes
- **Stage Titles**:
1. Mask Alignment
2. Object Understanding
3. Spatial Understanding
4. Referring Segmentation
- **UI Elements**:
- Purple buttons labeled "LLM" (with flame icon) in all stages.
- "LoRA" button (with flame icon) only in Stage 4.
- Labels: "Vision Encoder", "Region Encoder", "Mask Decoder" (with flame icons).
- Video/image icons (play/picture symbols) in bottom-left of each stage.
- Text blocks for captions, questions, and answers.
### Detailed Analysis
#### Stage 1: Mask Alignment
- **Caption**: "A single black kettle on the table."
- **Image**: Kitchen scene with a kettle highlighted in yellow.
- **Components**:
- "Vision Encoder" (left) and "Region Encoder" (center) with flame icons.
#### Stage 2: Object Understanding
- **Question**: "What is the purpose of <object>?"
- **Answer**: "It enhances flavor, adding umami and richness to dishes."
- **Image**: Kitchen with multiple objects (pot, kettle, etc.).
- **Components**: Same as Stage 1.
#### Stage 3: Spatial Understanding
- **Question**: "What is the distance of <object0> and <object1>?"
- **Answer**: "0.7m."
- **Image**: Room with furniture (table, chair) highlighted in yellow/green.
- **Components**: Same as Stage 1.
#### Stage 4: Referring Segmentation
- **Question**: "Can you segment the brown teddy bear located on the table in this video?"
- **Answer**: "Sure, it is [SEG]."
- **Image**: Video frame with a teddy bear highlighted in green.
- **Components**:
- "Mask Decoder" (center) with flame icon.
- Combined "LLM + LoRA" button (purple).
### Key Observations
1. **Progression**: Each stage increases in complexity, from single-object alignment (Stage 1) to multi-object spatial reasoning (Stage 3) and video-based segmentation (Stage 4).
2. **LLM Integration**: "LLM" buttons appear in all stages, suggesting language model involvement in understanding and segmentation.
3. **LoRA Addition**: Stage 4 introduces "LoRA", implying a specialized model variant for segmentation tasks.
4. **Visual Encoding**: Consistent use of "Vision Encoder" and "Region Encoder" across stages indicates foundational visual processing.
### Interpretation
This workflow illustrates a hierarchical approach to visual-language tasks:
- **Stage 1** focuses on basic object localization (mask alignment).
- **Stage 2** adds semantic understanding (object purpose).
- **Stage 3** introduces spatial relationships (distance measurement).
- **Stage 4** combines temporal and spatial reasoning for video segmentation.
The inclusion of "LoRA" in Stage 4 suggests a fine-tuned model for precise segmentation, while the consistent use of "LLM" highlights its role in bridging vision and language. The flame icons may symbolize computational intensity or model efficiency.
No numerical data or charts are present; the image emphasizes textual and visual components of a technical pipeline.