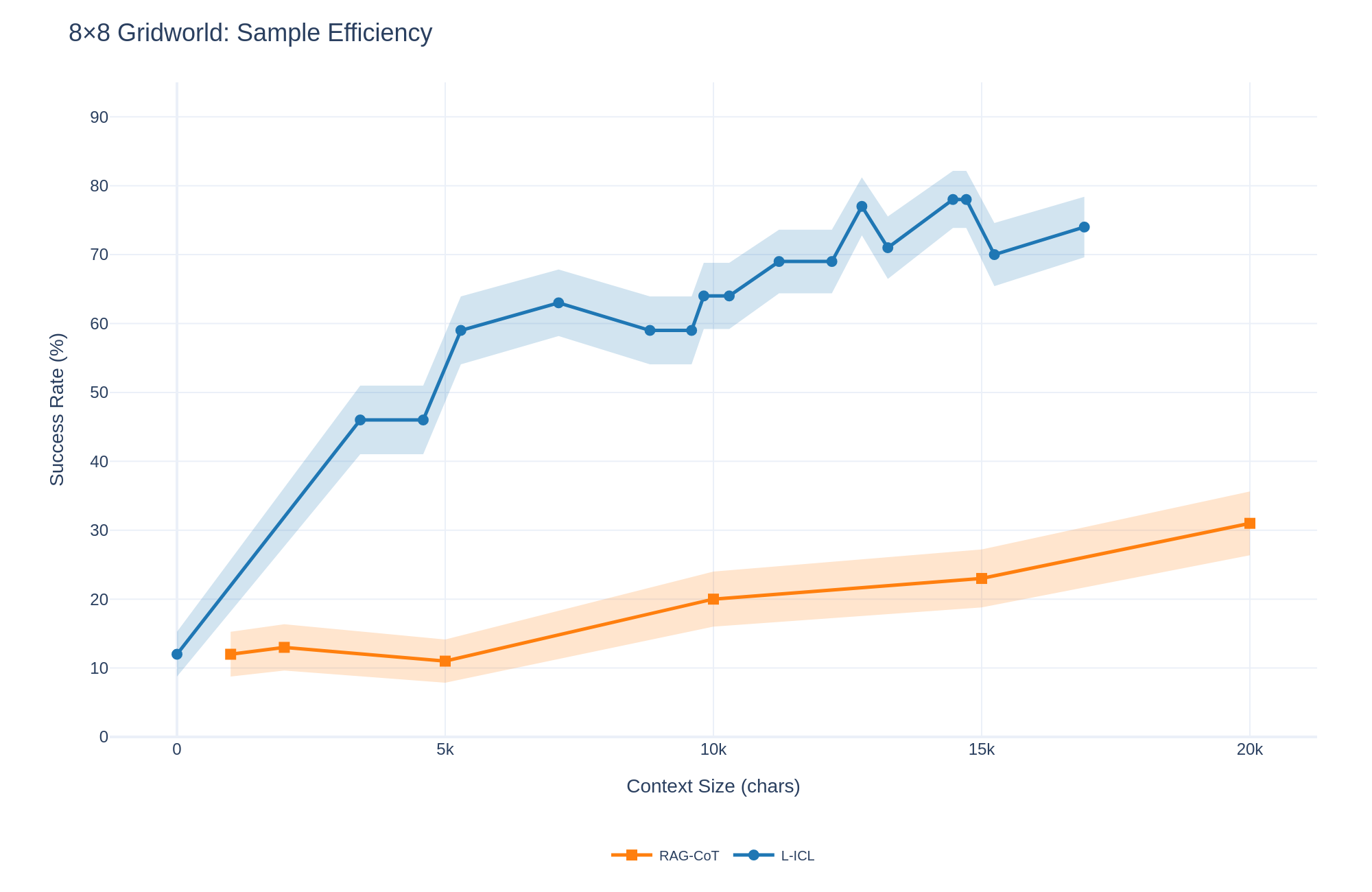
## Line Chart: 8x8 Gridworld: Sample Efficiency
### Overview
The chart compares the sample efficiency of two methods, **RAG-CoT** (orange) and **L-ICL** (blue), across varying context sizes (0 to 20,000 characters). Success rate (%) is plotted on the y-axis, with confidence intervals shaded around each line. The x-axis is labeled "Context Size (chars)" with markers at 0, 5k, 10k, 15k, and 20k. The legend is positioned at the bottom, with orange representing RAG-CoT and blue representing L-ICL.
### Components/Axes
- **X-axis**: "Context Size (chars)" with discrete markers at 0, 5,000, 10,000, 15,000, and 20,000 characters.
- **Y-axis**: "Success Rate (%)" ranging from 0% to 90% in 10% increments.
- **Legend**: Located at the bottom center, with orange squares for RAG-CoT and blue circles for L-ICL.
- **Shading**: Confidence intervals are shaded around both lines, with lighter blue for L-ICL and lighter orange for RAG-CoT.
### Detailed Analysis
#### RAG-CoT (Orange Line)
- **Data Points**:
- 0 chars: 12% (±2%)
- 5k chars: 11% (±3%)
- 10k chars: 20% (±4%)
- 15k chars: 23% (±3%)
- 20k chars: 31% (±5%)
- **Trend**: Steady upward slope with minimal fluctuation. Success rate increases consistently as context size grows, though the rate of improvement slows at larger context sizes.
#### L-ICL (Blue Line)
- **Data Points**:
- 0 chars: 12% (±2%)
- 5k chars: 46% (±5%)
- 10k chars: 59% (±4%)
- 15k chars: 79% (±6%)
- 20k chars: 74% (±7%)
- **Trend**: Sharp initial increase, peaking at 15k chars (79%), followed by a slight decline at 20k chars (74%). The confidence interval widens significantly at larger context sizes, indicating greater variability in performance.
### Key Observations
1. **Initial Parity**: Both methods start with identical success rates (12%) at 0 context size.
2. **Divergence at 5k Chars**: L-ICL outperforms RAG-CoT by 35 percentage points (46% vs. 11%) at 5k chars.
3. **Sustained Growth for RAG-CoT**: RAG-CoT shows consistent improvement, reaching 31% at 20k chars, though it remains far below L-ICL’s peak.
4. **L-ICL’s Plateau**: L-ICL’s success rate plateaus after 15k chars, with a minor decline at 20k chars, suggesting diminishing returns.
5. **Confidence Intervals**: L-ICL’s confidence intervals are broader, particularly at 20k chars (±7%), compared to RAG-CoT’s narrower intervals (±5% max).
### Interpretation
- **Sample Efficiency**: L-ICL demonstrates superior sample efficiency at mid-to-large context sizes (5k–15k chars), achieving near-doubling of success rates compared to RAG-CoT. However, its performance stabilizes and slightly regresses at 20k chars, raising questions about scalability.
- **RAG-CoT’s Consistency**: RAG-CoT’s steady growth suggests robustness in handling larger contexts, albeit at a slower rate. Its narrower confidence intervals imply more reliable performance across varying samples.
- **Practical Implications**: For applications requiring high success rates with moderate context sizes (e.g., 10k–15k chars), L-ICL is preferable. For scenarios prioritizing stability and scalability beyond 15k chars, RAG-CoT may be more suitable despite lower peak performance.
- **Anomalies**: The slight decline in L-ICL’s success rate at 20k chars warrants further investigation—potential overfitting or noise in the data at extreme context sizes.