# Technical Document Extraction: GRPO Workflow Diagram
## 1. Overview
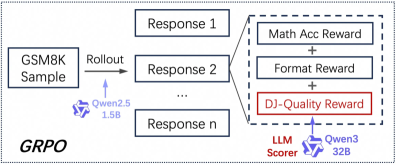
This image is a technical flow diagram illustrating the **Group Relative Policy Optimization (GRPO)** training process for a Large Language Model (LLM). It details the pipeline from initial sampling to the multi-component reward calculation used for reinforcement learning.
---
## 2. Component Isolation & Flow Analysis
The diagram flows from left to right, segmented into three primary stages: Input/Rollout, Response Generation, and Reward Scoring.
### Region A: Input and Rollout (Left)
* **Input Source:** A box labeled **"GSM8K Sample"**. This refers to the Grade School Math 8K dataset, commonly used for evaluating mathematical reasoning.
* **Action:** An arrow labeled **"Rollout"** points toward the generation stage.
* **Actor (Model):** Beneath the rollout arrow, a purple logo and text identify the model performing the rollout: **"Qwen2.5 1.5B"**.
### Region B: Response Generation (Center)
The rollout process generates a group of multiple outputs from the same prompt to facilitate relative comparison.
* **Response 1**: Top box.
* **Response 2**: Middle box.
* **...**: Ellipsis indicating multiple intermediate responses.
* **Response n**: Bottom box, representing the $n^{th}$ sample in the group.
### Region C: Reward Scoring Mechanism (Right)
A dashed bounding box expands from "Response 2" (serving as a representative example for the group) to show the internal logic of the reward function. The total reward is a summation of three distinct components:
1. **Math Acc Reward**: (Top box) Likely measures the correctness of the mathematical answer.
2. **+ (Addition Operator)**
3. **Format Reward**: (Middle box) Likely measures adherence to specific output formatting (e.g., using chain-of-thought tags).
4. **+ (Addition Operator)**
5. **DJ-Quality Reward**: (Bottom box, highlighted with a **red border**). This indicates a specific or custom quality metric being emphasized in this diagram.
* **Scorer Actor:** An arrow points to this specific reward component from a purple logo and text labeled **"Qwen3 32B"**.
* **Role Label:** This model is explicitly labeled as the **"LLM Scorer"**.
---
## 3. Textual Transcription
| Category | Transcribed Text |
| :--- | :--- |
| **Main Title/Process** | GRPO |
| **Input Data** | GSM8K Sample |
| **Process Step** | Rollout |
| **Primary Model** | Qwen2.5 1.5B |
| **Outputs** | Response 1, Response 2, ..., Response n |
| **Reward Component 1** | Math Acc Reward |
| **Reward Component 2** | Format Reward |
| **Reward Component 3** | DJ-Quality Reward |
| **Scoring Model** | Qwen3 32B |
| **Scoring Role** | LLM Scorer |
---
## 4. Technical Summary of Logic
The diagram describes a reinforcement learning setup where a smaller model (**Qwen2.5 1.5B**) generates multiple reasoning paths ("Rollouts") for a math problem. These responses are then evaluated. While standard rewards check for mathematical accuracy and formatting, a larger, more capable model (**Qwen3 32B**) acts as an "LLM Scorer" to provide a "DJ-Quality Reward," which likely evaluates the nuanced qualitative aspects of the reasoning process that cannot be captured by simple rule-based checks. This multi-faceted reward signal is then used to update the policy via the GRPO algorithm.