\n
## Diagram: GRPO Process Flow
### Overview
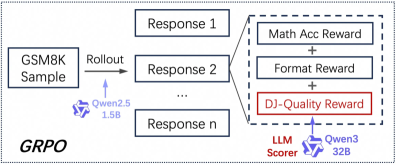
The image depicts a diagram illustrating the GRPO (likely an acronym for a process) workflow. A GSM8K sample is used as input, which is then processed through a model (Qwen2.5 1.5B) to generate multiple responses. These responses are then evaluated by an LLM Scorer (Qwen3 32B) to produce rewards based on Math Accuracy, Format, and DJ-Quality.
### Components/Axes
The diagram consists of the following components:
* **GSM8K Sample:** The initial input to the process.
* **Rollout:** An arrow indicating the process of generating responses from the GSM8K sample.
* **Qwen2.5 1.5B:** A model (indicated by a logo) used for generating responses.
* **Response 1, Response 2, ..., Response n:** Multiple responses generated by the Qwen2.5 1.5B model.
* **Math Acc Reward:** A reward component based on mathematical accuracy.
* **Format Reward:** A reward component based on the format of the response.
* **DJ-Quality Reward:** A reward component based on the DJ-Quality of the response (highlighted in red).
* **LLM Scorer:** An LLM (Qwen3 32B) used for scoring the responses.
* **Qwen3 32B:** The LLM model used for scoring (indicated by a logo).
* **GRPO:** Label at the bottom left of the diagram.
### Detailed Analysis / Content Details
The diagram shows a sequential process:
1. A **GSM8K Sample** is fed into the **Qwen2.5 1.5B** model.
2. The model generates multiple **Responses** (Response 1 to Response n).
3. These responses are then passed to the **LLM Scorer (Qwen3 32B)**.
4. The LLM Scorer evaluates each response and assigns three types of rewards: **Math Acc Reward**, **Format Reward**, and **DJ-Quality Reward**.
5. The **DJ-Quality Reward** is highlighted with a red border.
6. The flow of information is indicated by arrows. The arrow from GSM8K Sample to Response 1, 2, ... n is labeled "Rollout". The arrow from the responses to the DJ-Quality Reward is a dashed line, indicating a scoring process.
### Key Observations
* The diagram emphasizes the use of multiple responses (Response 1 to Response n) to improve the evaluation process.
* The **DJ-Quality Reward** is visually highlighted, suggesting its importance in the GRPO process.
* Two different LLM models are used: Qwen2.5 1.5B for response generation and Qwen3 32B for scoring.
* The diagram does not provide any numerical data or specific values for the rewards.
### Interpretation
The diagram illustrates a Reinforcement Learning from Human Feedback (RLHF) or similar process. The GRPO likely stands for a method of generating responses and then scoring them using an LLM to provide rewards. The rewards are then used to fine-tune the initial model (Qwen2.5 1.5B). The use of multiple responses and different reward components (Math Accuracy, Format, and DJ-Quality) suggests a comprehensive evaluation strategy. The highlighting of the DJ-Quality Reward indicates that this aspect is particularly important for the GRPO process. The diagram is a high-level overview and does not provide details on the specific algorithms or implementation details of the GRPO process. The diagram suggests a feedback loop where the rewards are used to improve the response generation model.