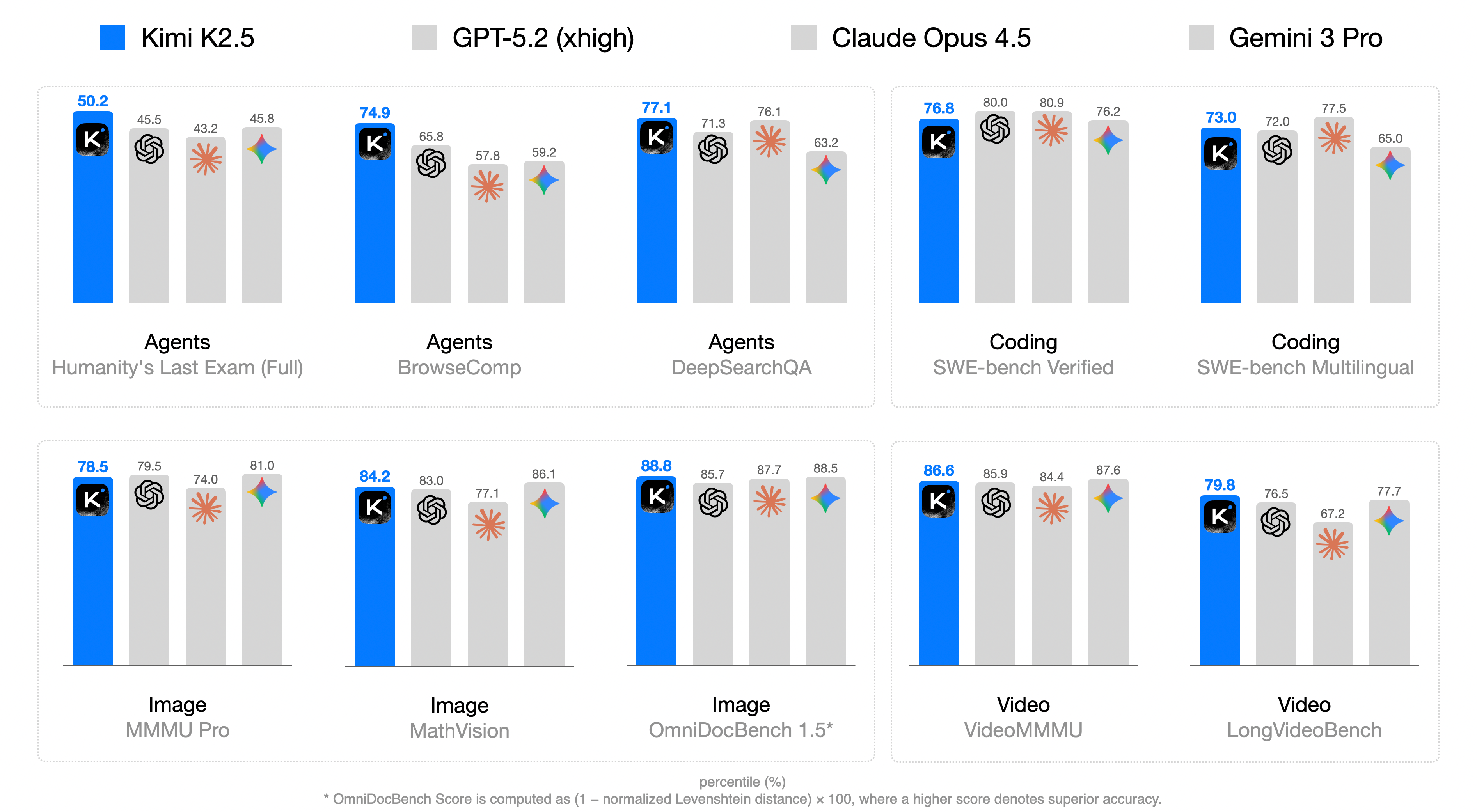
## Grouped Bar Chart: AI Model Performance Across Diverse Benchmarks
### Overview
This image is a grouped bar chart comparing the performance of four AI models—**Kimi K2.5** (blue bars), **GPT-5.2 (xhigh)** (light gray bars), **Claude Opus 4.5** (light gray bars with orange star icon), and **Gemini 3 Pro** (light gray bars with blue star icon)—across 10 benchmarks grouped into four categories: Agents, Coding, Image, and Video. Performance is measured in percentiles (%), with higher scores indicating better performance. A footnote clarifies the score calculation for one benchmark.
### Components/Axes
- **Legend (Top)**: Four models with distinct visual identifiers:
- Kimi K2.5: Blue bar + black square icon with white "K"
- GPT-5.2 (xhigh): Light gray bar + black spiral icon
- Claude Opus 4.5: Light gray bar + orange star icon
- Gemini 3 Pro: Light gray bar + blue star icon
- **Benchmark Categories (X-axis Groupings)**:
- Agents: Humanity's Last Exam (Full), BrowseComp, DeepSearchQA
- Coding: SWE-bench Verified, SWE-bench Multilingual
- Image: MMMU Pro, MathVision, OmniDocBench 1.5*
- Video: VideoMMMU, LongVideoBench
- **Score Metric**: Percentiles (%) (implied by the footnote and numerical labels above bars)
- **Footnote (Bottom)**: "* OmniDocBench Score is computed as (1 – normalized Levenshtein distance) × 100, where a higher score denotes superior accuracy."
### Detailed Analysis
Below are the percentile scores for each model across all benchmarks (scores labeled above bars):
#### Agents Category
| Benchmark | Kimi K2.5 | GPT-5.2 (xhigh) | Claude Opus 4.5 | Gemini 3 Pro |
|----------------------------|-----------|-----------------|-----------------|--------------|
| Humanity's Last Exam (Full)| 50.2 | 45.5 | 43.2 | 45.8 |
| BrowseComp | 74.9 | 65.8 | 57.8 | 59.2 |
| DeepSearchQA | 77.1 | 71.3 | 76.1 | 63.2 |
#### Coding Category
| Benchmark | Kimi K2.5 | GPT-5.2 (xhigh) | Claude Opus 4.5 | Gemini 3 Pro |
|----------------------------|-----------|-----------------|-----------------|--------------|
| SWE-bench Verified | 76.8 | 80.0 | 80.9 | 76.2 |
| SWE-bench Multilingual | 73.0 | 72.0 | 77.5 | 65.0 |
#### Image Category
| Benchmark | Kimi K2.5 | GPT-5.2 (xhigh) | Claude Opus 4.5 | Gemini 3 Pro |
|----------------------------|-----------|-----------------|-----------------|--------------|
| MMMU Pro | 78.5 | 79.5 | 74.0 | 81.0 |
| MathVision | 84.2 | 83.0 | 77.1 | 86.1 |
| OmniDocBench 1.5* | 88.8 | 85.7 | 87.7 | 88.5 |
#### Video Category
| Benchmark | Kimi K2.5 | GPT-5.2 (xhigh) | Claude Opus 4.5 | Gemini 3 Pro |
|----------------------------|-----------|-----------------|-----------------|--------------|
| VideoMMMU | 86.6 | 85.9 | 84.4 | 87.6 |
| LongVideoBench | 79.8 | 76.5 | 67.2 | 77.7 |
### Key Observations
1. **Agents Benchmarks**: Kimi K2.5 leads in all three agent-focused tasks (50.2–77.1), with a significant margin in BrowseComp (74.9 vs. next-highest 65.8).
2. **Coding Benchmarks**: Claude Opus 4.5 outperforms others in both SWE-bench tasks (80.9 in Verified, 77.5 in Multilingual), while GPT-5.2 is competitive in SWE-bench Verified (80.0).
3. **Image Benchmarks**: Gemini 3 Pro leads in MMMU Pro (81.0) and MathVision (86.1), while Kimi K2.5 narrowly leads in OmniDocBench 1.5 (88.8 vs. Gemini’s 88.5).
4. **Video Benchmarks**: Gemini 3 Pro leads in VideoMMMU (87.6), and Kimi K2.5 leads in LongVideoBench (79.8).
5. **Outlier**: Claude Opus 4.5 has a notably low score in LongVideoBench (67.2), far below the other three models (76.5–79.8).
6. **Consistency**: Kimi K2.5 is top or near-top in 8 of 10 benchmarks, showing strong cross-category performance.
### Interpretation
This chart illustrates the competitive landscape of leading AI models across specialized tasks. The percentile scores reflect relative performance within each benchmark, so higher values indicate better capability for that specific task. Key takeaways:
- **Kimi K2.5** excels in agent-oriented tasks (e.g., browsing, deep search) and document understanding (OmniDocBench 1.5), suggesting strong reasoning and information retrieval abilities.
- **Claude Opus 4.5** dominates coding benchmarks, indicating superior software engineering and code generation capabilities.
- **Gemini 3 Pro** performs best in image understanding tasks (MMMU Pro, MathVision), highlighting strengths in visual reasoning.
- The OmniDocBench 1.5 footnote clarifies that its score measures document accuracy via Levenshtein distance, making Kimi’s lead here meaningful for document processing use cases.
Overall, the data shows no single model dominates all tasks—each has niche strengths, which is critical for users selecting models for specific applications (e.g., coding vs. image analysis).