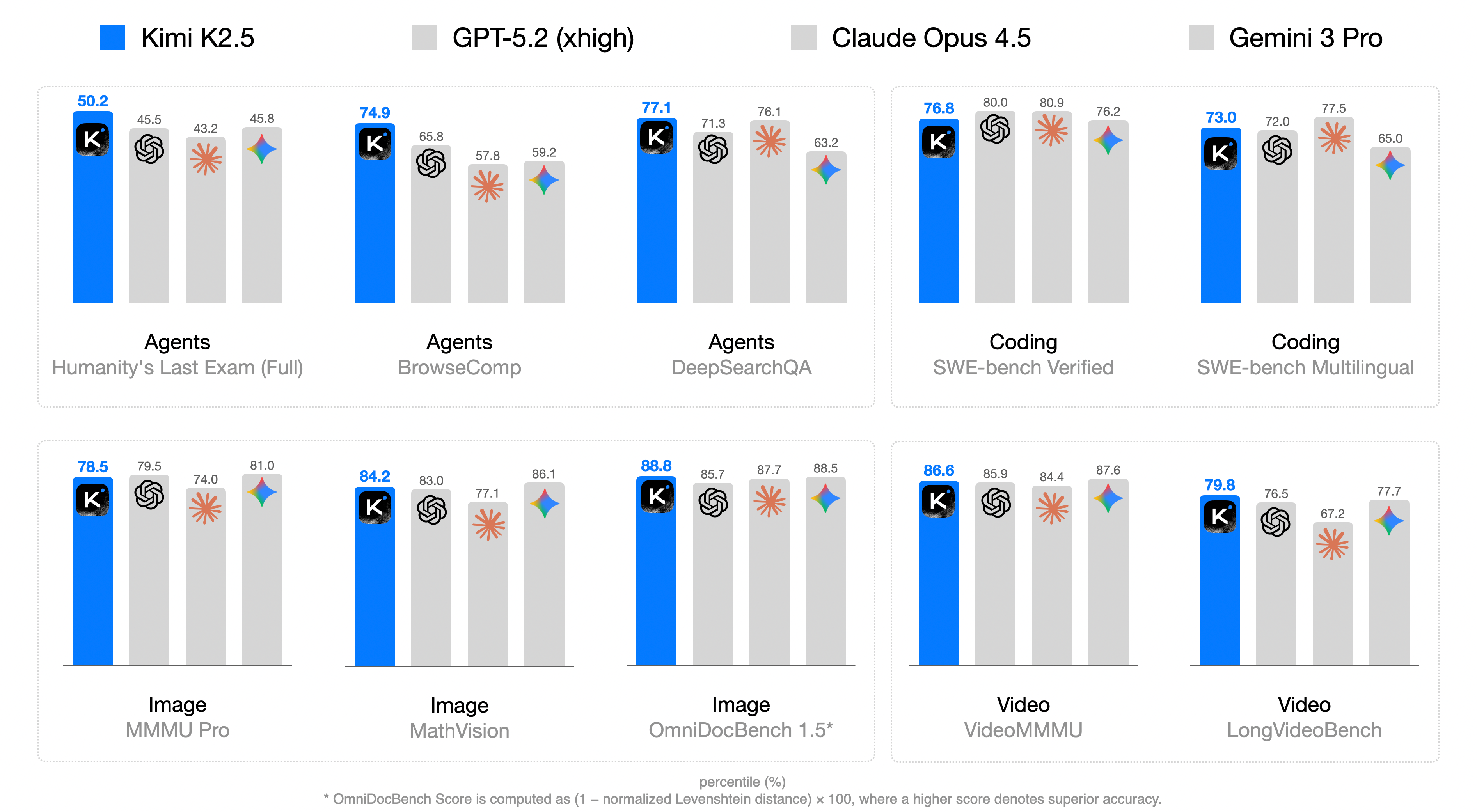
## Bar Chart: AI Model Performance Comparison Across Tasks
### Overview
The image displays a grouped bar chart comparing the performance of four AI models (Kimi K2.5, GPT-5.2 (xhigh), Claude Opus 4.5, Gemini 3 Pro) across six task categories: Agents (with subcategories), Coding, Image, and Video. Each bar represents a percentage score, with higher values indicating superior accuracy. The chart emphasizes Kimi K2.5's dominance across most tasks.
### Components/Axes
- **X-Axis**: Task categories and subcategories:
- Agents
- Humanity's Last Exam (Full)
- BrowseComp
- DeepSearchQA
- Coding
- SWE-bench Verified
- SWE-bench Multilingual
- Image
- MMU Pro
- MathVision
- OmniDocBench 1.5*
- Video
- VideoMMMU
- LongVideoBench
- **Y-Axis**: Percentage scores (0–100%), labeled "percentile (%)"
- **Legend**: Located at the top, mapping colors to models:
- Blue: Kimi K2.5
- Gray: GPT-5.2 (xhigh)
- Dark Gray: Claude Opus 4.5
- Light Gray: Gemini 3 Pro
- **Annotations**: Numerical values atop each bar (e.g., "50.2" for Kimi K2.5 in Agents/Humanity's Last Exam)
### Detailed Analysis
#### Agents
- **Humanity's Last Exam (Full)**:
- Kimi K2.5: 50.2 (blue)
- GPT-5.2 (xhigh): 45.5 (gray)
- Claude Opus 4.5: 43.2 (dark gray)
- Gemini 3 Pro: 45.8 (light gray)
- **BrowseComp**:
- Kimi K2.5: 74.9 (blue)
- GPT-5.2 (xhigh): 65.8 (gray)
- Claude Opus 4.5: 57.8 (dark gray)
- Gemini 3 Pro: 59.2 (light gray)
- **DeepSearchQA**:
- Kimi K2.5: 77.1 (blue)
- GPT-5.2 (xhigh): 71.3 (gray)
- Claude Opus 4.5: 76.1 (dark gray)
- Gemini 3 Pro: 63.2 (light gray)
#### Coding
- **SWE-bench Verified**:
- Kimi K2.5: 76.8 (blue)
- GPT-5.2 (xhigh): 80.0 (gray)
- Claude Opus 4.5: 80.9 (dark gray)
- Gemini 3 Pro: 76.2 (light gray)
- **SWE-bench Multilingual**:
- Kimi K2.5: 73.0 (blue)
- GPT-5.2 (xhigh): 72.0 (gray)
- Claude Opus 4.5: 77.5 (dark gray)
- Gemini 3 Pro: 65.0 (light gray)
#### Image
- **MMU Pro**:
- Kimi K2.5: 78.5 (blue)
- GPT-5.2 (xhigh): 79.5 (gray)
- Claude Opus 4.5: 74.0 (dark gray)
- Gemini 3 Pro: 81.0 (light gray)
- **MathVision**:
- Kimi K2.5: 84.2 (blue)
- GPT-5.2 (xhigh): 83.0 (gray)
- Claude Opus 4.5: 77.1 (dark gray)
- Gemini 3 Pro: 86.1 (light gray)
- **OmniDocBench 1.5***:
- Kimi K2.5: 88.8 (blue)
- GPT-5.2 (xhigh): 85.7 (gray)
- Claude Opus 4.5: 87.7 (dark gray)
- Gemini 3 Pro: 88.5 (light gray)
#### Video
- **VideoMMMU**:
- Kimi K2.5: 86.6 (blue)
- GPT-5.2 (xhigh): 85.9 (gray)
- Claude Opus 4.5: 84.4 (dark gray)
- Gemini 3 Pro: 87.6 (light gray)
- **LongVideoBench**:
- Kimi K2.5: 79.8 (blue)
- GPT-5.2 (xhigh): 76.5 (gray)
- Claude Opus 4.5: 67.2 (dark gray)
- Gemini 3 Pro: 77.7 (light gray)
### Key Observations
1. **Kimi K2.5 Dominance**: Consistently leads in most tasks (e.g., 88.8 in OmniDocBench 1.5*), with only minor exceptions (e.g., SWE-bench Verified, where Claude Opus 4.5 scores higher at 80.9).
2. **Claude Opus 4.5 Strengths**: Outperforms others in SWE-bench Verified (80.9) and LongVideoBench (67.2), though the latter is an outlier due to lower absolute scores.
3. **Gemini 3 Pro Variability**: Scores range from 43.2 (lowest in Agents/BrowseComp) to 88.5 (highest in Image/OmniDocBench 1.5*), showing inconsistent performance.
4. **Task-Specific Trends**:
- Coding tasks show tighter competition (GPT-5.2 and Claude Opus 4.5 often match Kimi K2.5).
- Image tasks highlight Gemini 3 Pro's peak performance (81.0 in MMU Pro).
- Video tasks reveal Kimi K2.5's slight edge in VideoMMMU (86.6 vs. Gemini 3 Pro's 87.6).
### Interpretation
The data suggests **Kimi K2.5** is the most balanced high-performer across diverse AI tasks, particularly excelling in image and document-based benchmarks. Its consistent scores (73–88.8 range) indicate robust architecture and training. **Claude Opus 4.5** shows niche strengths in coding and video tasks but lags in Agents. **Gemini 3 Pro**'s variability hints at potential overfitting or specialization gaps. The **OmniDocBench 1.5*** metric (88.8 for Kimi K2.5) underscores its document-processing prowess, while the asterisk notes its calculation method: `(1 - normalized Levenshtein distance) × 100`, emphasizing accuracy over raw output. This chart likely informs model selection for applications requiring cross-domain AI capabilities.