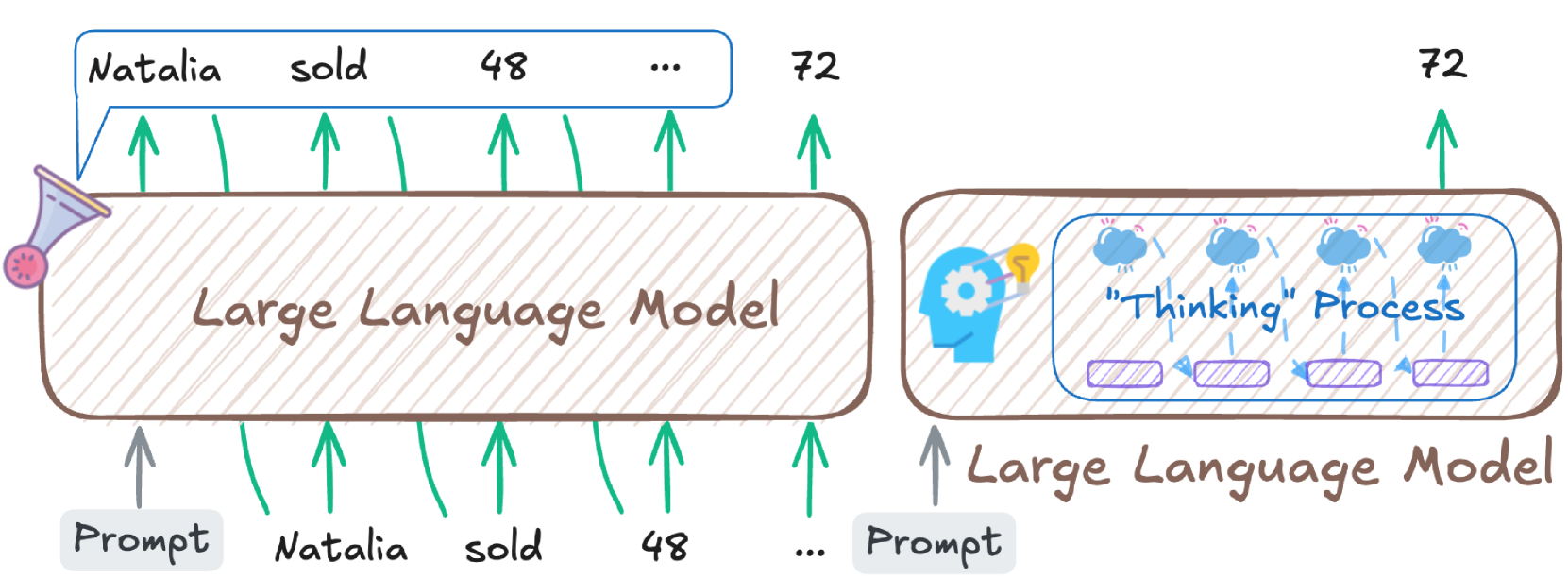
## Diagram: Large Language Model Processing Flow
### Overview
The diagram illustrates the workflow of a large language model (LLM) processing a textual prompt. It visually separates the input processing stage from the internal "thinking" process, using arrows to indicate data flow and symbolic elements to represent computational steps.
### Components/Axes
1. **Left Section (Input Processing):**
- **Prompt Input:** A text box labeled "Prompt" containing the phrase "Natalia sold 48..." with arrows pointing to each word ("Natalia," "sold," "48," "...").
- **Large Language Model:** A central rectangle labeled "Large Language Model" with green arrows connecting it to the prompt input.
- **Output Token Count:** A value "72" with an upward arrow pointing to the LLM, suggesting output generation.
2. **Right Section (Thinking Process):**
- **Brain Icon:** A stylized brain with a lightbulb and gears, symbolizing cognitive processing.
- **"Thinking Process" Box:** Contains three purple rectangles labeled "Thinking Steps" with arrows indicating sequential processing.
- **Output Token Count:** The same "72" value from the left section, linked to the thinking process via a green arrow.
### Detailed Analysis
- **Input Parsing:** The prompt "Natalia sold 48..." is broken into discrete tokens ("Natalia," "sold," "48," "..."), with arrows showing their sequential input into the model.
- **Token Counts:**
- "48" appears as a numerical token in the input, likely representing a quantity (e.g., items sold).
- "72" is repeated in both sections, possibly indicating the total token count of the generated output or intermediate processing steps.
- **Thinking Process:** The three purple rectangles in the "Thinking Process" box suggest iterative reasoning steps (e.g., parsing, computation, output generation).
### Key Observations
- The model processes the input phrase token-by-token, with explicit numerical tokens ("48," "72") highlighted.
- The "Thinking Process" is abstracted into discrete steps, emphasizing the model's internal logic.
- The repetition of "72" implies a consistent output size or computational step count.
### Interpretation
This diagram simplifies the LLM's operation into two stages:
1. **Input Tokenization:** The prompt is segmented into words and numbers, with "48" acting as a critical data point (e.g., a quantity in a sales context).
2. **Cognitive Workflow:** The "Thinking Process" represents the model's internal mechanisms, such as context analysis, pattern recognition, and output generation. The "72" token count may reflect the model's output length or the number of computational steps required to resolve the input.
The use of arrows and symbolic elements (brain, gears) emphasizes the model's structured yet complex reasoning. The repetition of "72" suggests a fixed output format or optimization for efficiency.