## Diagram: DeepSeek Model Training Flow
### Overview
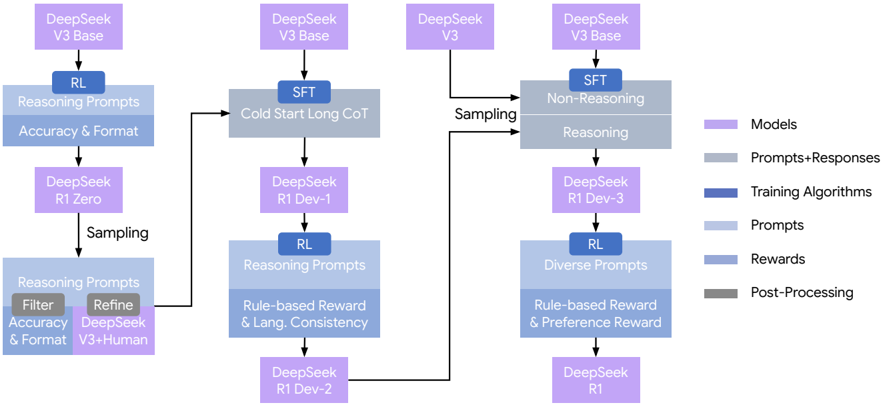
The image presents a diagram illustrating the training flow of DeepSeek models. It outlines different training paths and components, including models, prompts, training algorithms, and rewards. The diagram shows three distinct training pathways, each starting with a DeepSeek model and progressing through various stages of prompting, reasoning, and reward mechanisms.
### Components/Axes
* **Models:** Represented by light purple rectangles. Examples include "DeepSeek V3 Base," "DeepSeek V3," "DeepSeek R1 Zero," "DeepSeek R1 Dev-1," "DeepSeek R1 Dev-2," "DeepSeek R1 Dev-3," and "DeepSeek R1."
* **Prompts+Responses:** Represented by light gray rectangles. Examples include "Reasoning," "Non-Reasoning," and "Cold Start Long CoT."
* **Training Algorithms:** Represented by dark blue rectangles. Examples include "RL" (Reinforcement Learning) and "SFT" (Supervised Fine-Tuning).
* **Prompts:** Represented by light blue rectangles. Examples include "Reasoning Prompts," "Diverse Prompts," and "Filter Accuracy & Format, Refine DeepSeek V3+Human."
* **Rewards:** Represented by dark gray rectangles. Examples include "Rule-based Reward & Lang. Consistency" and "Rule-based Reward & Preference Reward."
* **Post-Processing:** Represented by dark gray rectangles.
* **Arrows:** Indicate the flow of data and processes between components.
* **Sampling:** Indicates a branching point where data is sampled.
**Legend (Located on the right side of the diagram):**
* Models: Light Purple
* Prompts+Responses: Light Gray
* Training Algorithms: Dark Blue
* Prompts: Light Blue
* Rewards: Dark Gray
* Post-Processing: Dark Gray
### Detailed Analysis
**Pathway 1 (Leftmost):**
1. Starts with "DeepSeek V3 Base" (light purple).
2. Goes through "RL" (Reinforcement Learning - dark blue) applied to "Reasoning Prompts" and "Accuracy & Format" (light blue).
3. Proceeds to "DeepSeek R1 Zero" (light purple).
4. "Sampling" occurs.
5. The sampled data is processed through "Reasoning Prompts" which includes "Filter Accuracy & Format" and "Refine DeepSeek V3+Human" (light blue).
**Pathway 2 (Middle):**
1. Starts with "DeepSeek V3 Base" (light purple).
2. Goes through "SFT" (Supervised Fine-Tuning - dark blue) applied to "Cold Start Long CoT" (light gray).
3. Proceeds to "DeepSeek R1 Dev-1" (light purple).
4. Goes through "RL" (Reinforcement Learning - dark blue) applied to "Reasoning Prompts" and "Rule-based Reward & Lang. Consistency" (light blue).
5. Proceeds to "DeepSeek R1 Dev-2" (light purple).
6. A feedback loop connects "DeepSeek R1 Dev-2" back to the "Reasoning Prompts" stage of Pathway 1.
**Pathway 3 (Rightmost):**
1. Starts with "DeepSeek V3" (light purple) and "DeepSeek V3 Base" (light purple).
2. Both pathways are "Sampling".
3. Goes through "SFT" (Supervised Fine-Tuning - dark blue) applied to "Non-Reasoning" and "Reasoning" (light gray).
4. Proceeds to "DeepSeek R1 Dev-3" (light purple).
5. Goes through "RL" (Reinforcement Learning - dark blue) applied to "Diverse Prompts" and "Rule-based Reward & Preference Reward" (light blue).
6. Proceeds to "DeepSeek R1" (light purple).
### Key Observations
* The diagram illustrates three distinct training pathways for DeepSeek models.
* Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) are key training algorithms used.
* The models progress through stages of prompting, reasoning, and reward mechanisms.
* Sampling is used to branch the training process.
* There is a feedback loop from "DeepSeek R1 Dev-2" to the "Reasoning Prompts" stage of Pathway 1.
### Interpretation
The diagram provides a high-level overview of the training process for DeepSeek models. It highlights the use of different training algorithms, prompting strategies, and reward mechanisms to optimize model performance. The presence of multiple pathways and sampling suggests that different training approaches are being explored and compared. The feedback loop indicates an iterative refinement process where the model's performance is used to adjust the training process. The diagram suggests a complex and multifaceted approach to training DeepSeek models, incorporating both supervised and reinforcement learning techniques.