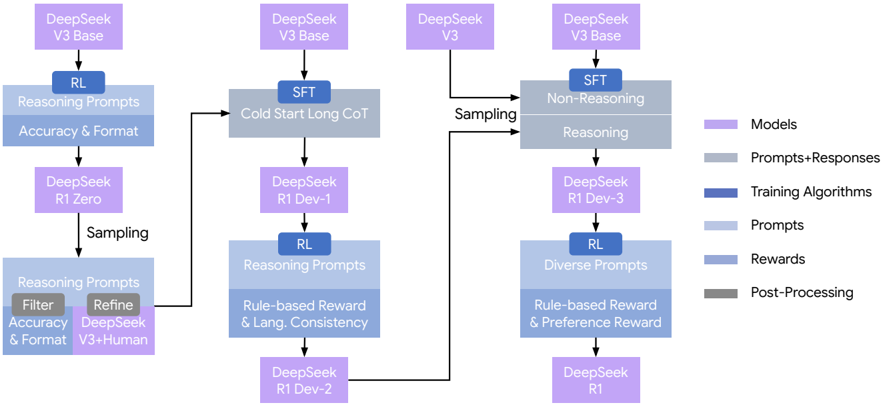
## Diagram: DeepSeek Model Training Pipeline
### Overview
The image is a technical flowchart illustrating the training and refinement pipeline for the DeepSeek series of AI models. It depicts a multi-stage process starting from base models, applying various training algorithms (Reinforcement Learning - RL, Supervised Fine-Tuning - SFT), using different prompt types, and resulting in progressively refined model versions. The flow is primarily from left to right and top to bottom, with branching and merging paths.
### Components/Axes
The diagram is composed of interconnected boxes and arrows, color-coded according to a legend on the right side.
**Legend (Right Side):**
* **Models (Light Purple):** Represents the AI model at various stages.
* **Prompts+Responses (Light Gray):** Represents the data used for training.
* **Training Algorithms (Dark Blue):** Represents the core training methods (RL, SFT).
* **Prompts (Light Blue):** Represents the input prompts used.
* **Rewards (Medium Blue):** Represents the reward signals used in RL.
* **Post-Processing (Dark Gray):** Represents filtering and refinement steps.
**Spatial Layout:**
* The pipeline begins at the top-left with "DeepSeek V3 Base".
* The legend is positioned vertically along the right edge of the diagram.
* The flow splits into three main vertical columns or branches that eventually converge.
### Detailed Analysis
The pipeline can be segmented into three primary processing branches:
**1. Left Branch (Initial RL & Refinement):**
* **Start:** `DeepSeek V3 Base` (Model).
* **Step 1:** Applies `RL` (Training Algorithm) using `Reasoning Prompts` (Prompt) focused on `Accuracy & Format` (Reward).
* **Output:** `DeepSeek R1 Zero` (Model).
* **Step 2:** `Sampling` (Process) from `DeepSeek R1 Zero` generates `Reasoning Prompts` (Prompt).
* **Step 3:** These prompts undergo `Post-Processing` via `Filter` (for `Accuracy & Format`) and `Refine` (using `DeepSeek V3+Human` input).
* **Connection:** The output of this refinement feeds into the middle branch.
**2. Middle Branch (Cold Start & Iterative RL):**
* **Start:** `DeepSeek V3 Base` (Model).
* **Step 1:** Applies `SFT` (Training Algorithm) using `Cold Start Long CoT` (Prompt+Response).
* **Output:** `DeepSeek R1 Dev-1` (Model).
* **Step 2:** Applies `RL` (Training Algorithm) using `Reasoning Prompts` (Prompt) with `Rule-based Reward & Lang. Consistency` (Reward).
* **Output:** `DeepSeek R1 Dev-2` (Model).
* **Connection:** This branch receives input from the Left Branch's post-processing step and its output feeds into the Right Branch.
**3. Right Branch (Final SFT & RL):**
* **Start:** `DeepSeek V3 Base` (Model) and `DeepSeek V3` (Model, from an external source indicated by an arrow).
* **Step 1:** Applies `SFT` (Training Algorithm) using a combination of `Non-Reasoning` and `Reasoning` (Prompt+Response) data, which is generated via `Sampling`.
* **Output:** `DeepSeek R1 Dev-3` (Model).
* **Step 2:** Applies `RL` (Training Algorithm) using `Diverse Prompts` (Prompt) with `Rule-based Reward & Preference Reward` (Reward).
* **Final Output:** `DeepSeek R1` (Model).
### Key Observations
* **Iterative Refinement:** The process is highly iterative, with models (`R1 Zero`, `R1 Dev-1`, `R1 Dev-2`, `R1 Dev-3`) serving as intermediate checkpoints before the final `DeepSeek R1`.
* **Hybrid Training:** The pipeline combines Supervised Fine-Tuning (SFT) with Reinforcement Learning (RL) at multiple stages.
* **Prompt Diversity:** Training uses a variety of prompt types: `Reasoning Prompts`, `Cold Start Long CoT`, `Non-Reasoning`, and `Diverse Prompts`.
* **Complex Reward Systems:** RL stages employ different reward mechanisms, evolving from simple `Accuracy & Format` to more complex `Rule-based Reward & Lang. Consistency` and finally `Rule-based Reward & Preference Reward`.
* **Human & Model Integration:** The `Refine` step in the left branch explicitly incorporates both `DeepSeek V3` model output and `Human` input.
* **Sampling as a Connector:** `Sampling` is used as a key process to generate training data from intermediate models.
### Interpretation
This diagram details a sophisticated, multi-path training curriculum designed to create the `DeepSeek R1` model. It suggests a philosophy of starting with a strong base (`V3 Base`), creating an initial reasoning-focused model (`R1 Zero`), and then using that model's outputs to "cold start" a more capable development model (`R1 Dev-1`). Parallel tracks likely explore different training methodologies (e.g., pure reasoning vs. mixed reasoning/non-reasoning SFT).
The convergence of branches into the final `R1 Dev-3` and then `DeepSeek R1` indicates an ensemble or best-of-breed approach, where insights and data products from different experimental paths are combined. The progression of reward functions from format-focused to preference-focused implies a training strategy that first instills basic structural competence and then refines the model's outputs to align with human preferences or other quality metrics. The entire pipeline emphasizes iterative improvement, data generation from intermediate models, and the strategic combination of supervised and reinforcement learning techniques.