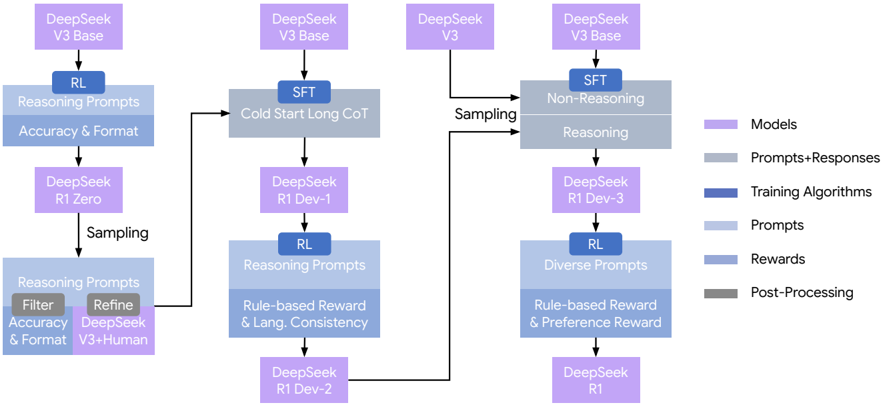
## Flowchart: DeepSeek Model Development Pipeline
### Overview
The image depicts a multi-stage development pipeline for DeepSeek language models, showing iterative refinement processes from base models to specialized versions. The flowchart uses color-coded components to represent different stages and elements of the development process.
### Components/Axes
**Legend (right side):**
- Purple: Models (DeepSeek V3 Base, R1 Zero, R1 Dev-1, R1 Dev-2, R1)
- Gray: Prompts+Responses
- Blue: Training Algorithms (RL, SFT)
- Light Blue: Prompts
- Dark Blue: Rewards
- Dark Gray: Post-Processing
**Key Elements:**
1. **Models** (Purple boxes):
- DeepSeek V3 Base (appears 4x)
- DeepSeek R1 Zero
- DeepSeek R1 Dev-1
- DeepSeek R1 Dev-2
- DeepSeek R1
2. **Training Algorithms** (Blue boxes):
- RL (Reinforcement Learning)
- SFT (Supervised Fine-Tuning)
3. **Prompts** (Light Blue boxes):
- Reasoning Prompts
- Diverse Prompts
- Rule-based Reward & Lang. Consistency
- Rule-based Reward & Preference Reward
4. **Processes** (Gray boxes):
- Sampling
- Filter
- Refine
- Cold Start Long CoT
- Non-Reasoning Reasoning
### Detailed Analysis
**Flow Structure:**
1. **Left Branch (Accuracy & Format Focus):**
- DeepSeek V3 Base → RL (Reasoning Prompts) → DeepSeek R1 Zero
- Sampling → Filter → Refine → DeepSeek V3 + Human
- Final output: Refined Reasoning Prompts
2. **Center Branch (Cold Start Long CoT):**
- DeepSeek V3 Base → SFT → Cold Start Long CoT
- DeepSeek R1 Dev-1 → RL (Rule-based Reward & Lang. Consistency)
- Output: DeepSeek R1 Dev-2
3. **Right Branch (Diverse Prompts):**
- DeepSeek V3 Base → SFT → Non-Reasoning Reasoning
- DeepSeek R1 Dev-3 → RL (Rule-based Reward & Preference Reward)
- Output: DeepSeek R1
**Spatial Grounding:**
- Legend positioned on the right side
- Main flowchart divided into three vertical sections
- Model versions arranged in descending order from top to bottom
- Training algorithms (RL/SFT) positioned between model versions
- Prompts/rewards located in lower sections
**Textual Elements:**
- All model names in purple boxes
- Training algorithms in blue boxes
- Prompts in light blue boxes
- Rewards in dark blue boxes
- Processes in gray boxes
### Key Observations
1. Iterative refinement process from base model (V3) to specialized versions (R1)
2. Dual training approaches: RL for reasoning capabilities and SFT for foundational learning
3. Progressive complexity in prompts and rewards across development stages
4. Explicit separation between reasoning and non-reasoning pathways
5. Human-in-the-loop component in the left branch (V3 + Human)
### Interpretation
This pipeline demonstrates a systematic approach to developing advanced language models through:
1. **Progressive Specialization:** Starting with general capabilities (V3 Base) and refining through multiple development stages (R1 Zero → R1 Dev → R1)
2. **Hybrid Training:** Combining supervised learning (SFT) with reinforcement learning (RL) to balance breadth and depth of knowledge
3. **Quality Control:** Multiple filtering/refinement steps and human evaluation components
4. **Performance Optimization:** Use of rule-based rewards for language consistency and preference alignment
The flowchart suggests a research-driven development methodology focused on enhancing reasoning capabilities while maintaining linguistic consistency and human alignment. The separation of reasoning and non-reasoning pathways indicates an intentional design choice to optimize different aspects of model performance.