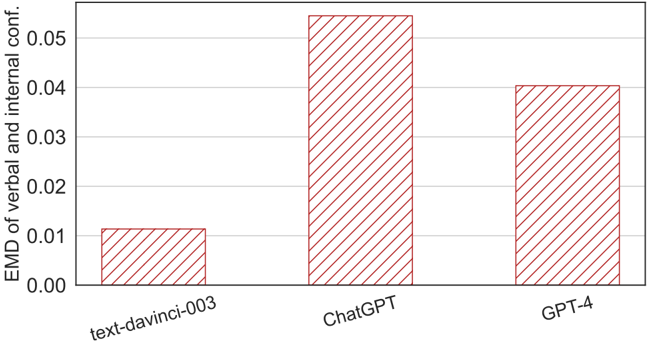
## Bar Chart: EMD of Verbal and Internal Confidence Across Models
### Overview
The image is a bar chart comparing the Emotional Distance Metric (EMD) of "verbal and internal conf." (confidence) across three AI models: `text-davinci-003`, `ChatGPT`, and `GPT-4`. The y-axis represents EMD values (0.00–0.05), while the x-axis lists the models. Bars are red with diagonal stripe patterns.
### Components/Axes
- **X-axis**: Labeled "text-davinci-003", "ChatGPT", "GPT-4" (left to right).
- **Y-axis**: Labeled "EMD of verbal and internal conf." with a scale from 0.00 to 0.05 in increments of 0.01.
- **Bars**: Red with diagonal stripe patterns (no explicit legend, but consistent styling across all bars).
- **Values**: Approximate EMD values are annotated on top of each bar:
- `text-davinci-003`: ~0.01
- `ChatGPT`: ~0.05
- `GPT-4`: ~0.04
### Detailed Analysis
- **`text-davinci-003`**: Shortest bar, EMD ~0.01 (lowest confidence variability).
- **`ChatGPT`**: Tallest bar, EMD ~0.05 (highest confidence variability).
- **`GPT-4`**: Intermediate bar, EMD ~0.04 (moderate confidence variability).
- **Stripe Patterns**: Uniform across all bars, suggesting no categorical differentiation beyond model names.
### Key Observations
1. **ChatGPT** exhibits the highest EMD, indicating greater variability in verbal/internal confidence compared to the other models.
2. **GPT-4** shows a slightly lower EMD than ChatGPT but higher than `text-davinci-003`.
3. **`text-davinci-003`** has the lowest EMD, suggesting more consistent verbal/internal confidence.
4. No legend is present, but the uniform stripe pattern implies no additional categorical groupings.
### Interpretation
The data suggests that `ChatGPT` demonstrates the greatest emotional distance in verbal and internal confidence, potentially reflecting differences in model architecture, training data, or response generation strategies. `GPT-4` and `text-davinci-003` show progressively lower EMD values, with `text-davinci-003` being the most consistent. The absence of a legend limits direct comparison of stripe patterns, but their uniformity suggests they are purely aesthetic. The trend aligns with expectations that newer or more advanced models (e.g., GPT-4) might balance consistency and variability differently than earlier iterations like `text-davinci-003`.