\n
## Bar Chart: EMD of Verbal and Internal Confidence
### Overview
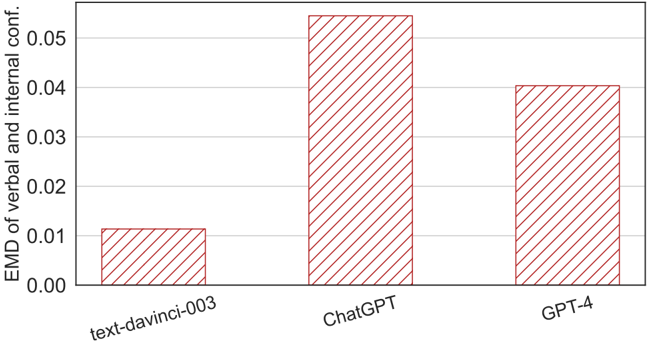
The image presents a bar chart comparing the Earth Mover's Distance (EMD) of verbal and internal confidence across three language models: text-davinci-003, ChatGPT, and GPT-4. The chart visually represents the EMD values for each model, allowing for a direct comparison of their performance.
### Components/Axes
* **X-axis:** Represents the language models: "text-davinci-003", "ChatGPT", and "GPT-4".
* **Y-axis:** Labeled "EMD of verbal and internal conf.", representing the Earth Mover's Distance, with a scale ranging from 0.00 to 0.06.
* **Bars:** Each bar corresponds to a language model, with the height of the bar indicating the EMD value. All bars are filled with a red diagonal hatch pattern.
### Detailed Analysis
* **text-davinci-003:** The bar for text-davinci-003 reaches approximately 0.012 on the Y-axis.
* **ChatGPT:** The bar for ChatGPT reaches approximately 0.055 on the Y-axis. This is the highest value among the three models.
* **GPT-4:** The bar for GPT-4 reaches approximately 0.042 on the Y-axis.
### Key Observations
ChatGPT exhibits the highest EMD value, indicating the largest discrepancy between its verbal and internal confidence. text-davinci-003 has the lowest EMD value, suggesting the closest alignment between its verbal and internal confidence. GPT-4 falls in between the two, with a moderate EMD value.
### Interpretation
The EMD metric quantifies the difference between the distributions of verbal and internal confidence. A higher EMD suggests a greater divergence, potentially indicating that the model's expressed confidence doesn't accurately reflect its internal assessment.
The data suggests that ChatGPT, while powerful, may be less calibrated in its confidence estimations compared to text-davinci-003 and GPT-4. This could have implications for applications where reliable confidence scores are crucial, such as decision-making or risk assessment. The lower EMD for text-davinci-003 might indicate a more conservative or accurate self-assessment of its predictions. GPT-4 represents a middle ground, potentially balancing performance with confidence calibration.
The chart highlights the importance of evaluating not only the accuracy of language models but also the reliability of their confidence scores. A model that consistently overestimates or underestimates its confidence can be problematic, even if its overall accuracy is high. Further investigation into the sources of these discrepancies could lead to improvements in model calibration and trustworthiness.