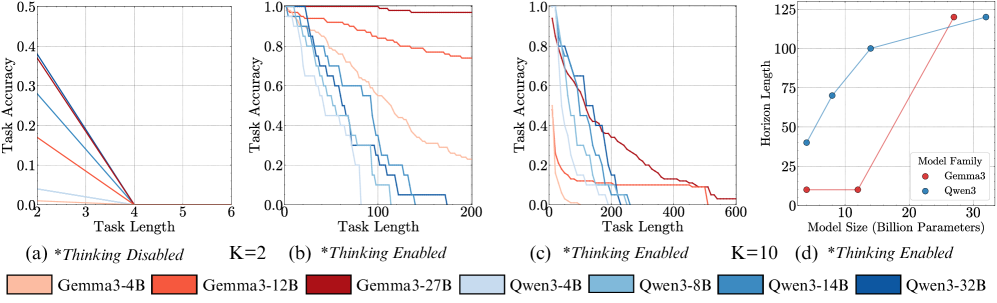
# Technical Document Extraction: Task Accuracy Analysis
## Chart (a) *Thinking Disabled* K=2
- **Title**: *Thinking Disabled* K=2
- **X-axis**: Task Length (2–6)
- **Y-axis**: Task Accuracy (0.0–0.5)
- **Legend**: Bottom-left
- **Colors/Labels**:
- Light orange: Gemma3-4B
- Orange: Gemma3-12B
- Dark red: Gemma3-27B
- Light blue: Qwen3-4B
- **Trends**:
- All lines slope downward as task length increases.
- Gemma3-27B starts highest (0.45 at task length 2), Qwen3-4B lowest (0.15 at task length 2).
- Lines converge near task length 6 (all ~0.05 accuracy).
## Chart (b) *Thinking Enabled*
- **Title**: *Thinking Enabled*
- **X-axis**: Task Length (0–200)
- **Y-axis**: Task Accuracy (0.0–1.0)
- **Legend**: Bottom-left
- **Colors/Labels**:
- Light orange: Gemma3-4B
- Orange: Gemma3-12B
- Dark red: Gemma3-27B
- Light blue: Qwen3-4B
- Blue: Qwen3-8B
- Teal: Qwen3-14B
- Dark blue: Qwen3-32B
- **Trends**:
- All lines decline with increasing task length.
- Gemma3-27B starts highest (0.95 at task length 0), Qwen3-32B lowest (0.75 at task length 0).
- Qwen3-32B plateaus near 0.6 at task length 200; Gemma3-27B drops to ~0.3.
## Chart (c) *Thinking Enabled* K=10
- **Title**: *Thinking Enabled* K=10
- **X-axis**: Task Length (0–600)
- **Y-axis**: Task Accuracy (0.0–1.0)
- **Legend**: Bottom-left
- **Colors/Labels**:
- Light orange: Gemma3-4B
- Orange: Gemma3-12B
- Dark red: Gemma3-27B
- Light blue: Qwen3-4B
- Blue: Qwen3-8B
- Teal: Qwen3-14B
- Dark blue: Qwen3-32B
- **Trends**:
- Steeper decline for Gemma3 models vs. Qwen3.
- Qwen3-32B maintains ~0.5 accuracy at task length 600; Gemma3-27B drops to ~0.1.
## Chart (d) Model Size vs. Horizon Length
- **Title**: *Thinking Enabled*
- **X-axis**: Model Size (Billion Parameters) (10–30B)
- **Y-axis**: Horizon Length (0–125)
- **Legend**: Bottom-right
- **Colors/Labels**:
- Red: Gemma3
- Blue: Qwen3
- **Trends**:
- Qwen3 models show linear increase in horizon length with model size (e.g., 40 → 120 as size increases from 10B to 32B).
- Gemma3 models remain flat (~10 horizon length across all sizes).
## Key Observations
1. **Model Performance**:
- Larger models (e.g., Gemma3-27B, Qwen3-32B) generally outperform smaller variants in task accuracy.
- Qwen3 models exhibit better scalability in horizon length with increased model size.
2. **Task Complexity**:
- Task accuracy degrades significantly with longer task lengths, especially under "Thinking Disabled" conditions.
- Enabling thinking (K=2, K=10) mitigates accuracy loss but does not eliminate it entirely.
3. **Efficiency Trade-offs**:
- Qwen3 models achieve higher horizon lengths at comparable computational costs (model size) compared to Gemma3.
## Notes
- All charts use line plots except (d), which uses scatter points.
- No non-English text detected.
- Spatial grounding confirms legend placement matches visual alignment in all charts.