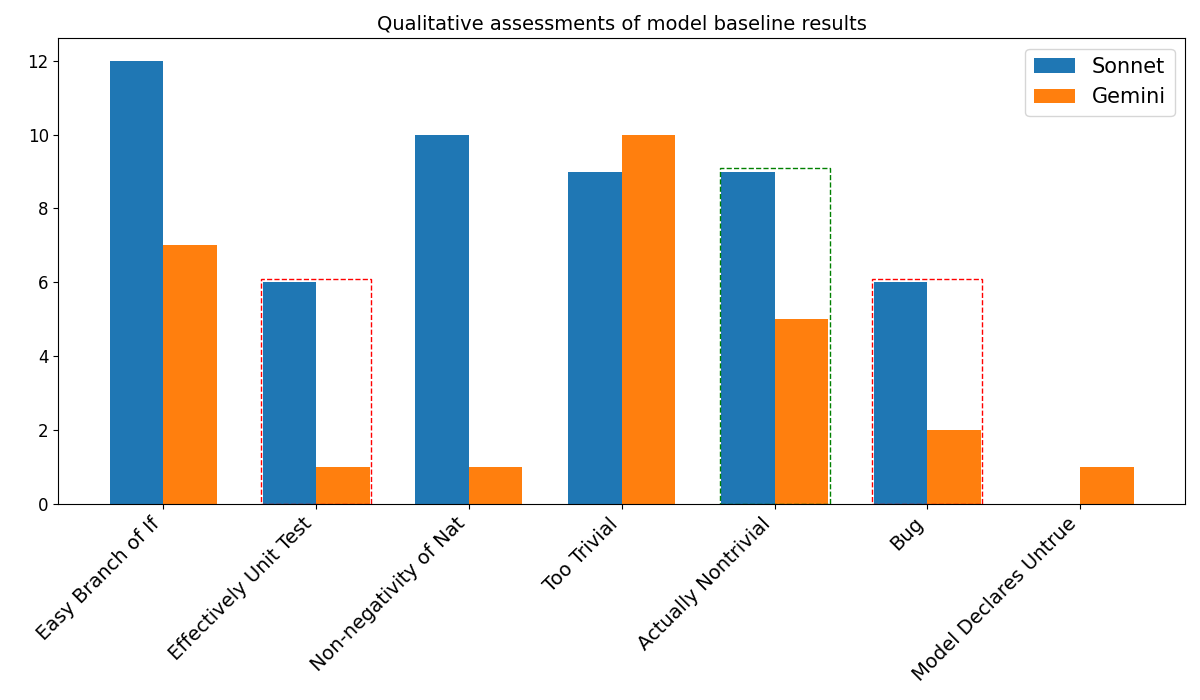
## Bar Chart: Qualitative assessments of model baseline results
### Overview
The chart compares qualitative assessment scores between two AI models (Sonnet and Gemini) across seven evaluation categories. Scores range from 0 to 12 on the y-axis, with distinct performance patterns emerging between the models.
### Components/Axes
- **X-axis**: Seven evaluation categories:
1. Easy Branch of If
2. Effectively Unit Test
3. Non-negativity of Nat
4. Too Trivial
5. Actually Nontrivial
6. Bug
7. Model Declares Untrue
- **Y-axis**: Qualitative assessment scores (0-12)
- **Legend**:
- Blue = Sonnet
- Orange = Gemini
- **Visual markers**:
- Red dashed lines at y=6 (categories 2, 6)
- Green dashed line at y=9 (category 5)
### Detailed Analysis
1. **Easy Branch of If**:
- Sonnet: ~12 (highest score)
- Gemini: ~7
2. **Effectively Unit Test**:
- Sonnet: ~6 (red threshold line)
- Gemini: ~1
3. **Non-negativity of Nat**:
- Sonnet: ~10
- Gemini: ~1
4. **Too Trivial**:
- Sonnet: ~9
- Gemini: ~10 (first category where Gemini outperforms)
5. **Actually Nontrivial**:
- Sonnet: ~9 (green benchmark line)
- Gemini: ~5
6. **Bug**:
- Both models: ~6 (red threshold line)
7. **Model Declares Untrue**:
- Sonnet: 0
- Gemini: ~1
### Key Observations
- Sonnet dominates in complex reasoning tasks (Non-negativity of Nat, Easy Branch of If)
- Gemini excels in simpler/trivial assessments (Too Trivial, Model Declares Untrue)
- Red threshold lines at y=6 appear in two categories (Effectively Unit Test, Bug)
- Green benchmark line at y=9 in "Actually Nontrivial" suggests target performance
- Significant performance gap in "Non-negativity of Nat" (10 vs 1)
### Interpretation
The data suggests Sonnet demonstrates superior capability in handling complex logical structures and edge cases, particularly in non-trivial scenarios. Gemini shows strength in basic assessments and error declaration accuracy. The red threshold lines may represent minimum acceptable performance benchmarks, while the green line at y=9 could indicate an ideal target for complex reasoning tasks. Notably, Sonnet's perfect score in "Easy Branch of If" contrasts sharply with its zero in "Model Declares Untrue," highlighting potential trade-offs between accuracy and error handling in different evaluation dimensions.